| By: | Steve Pepper, Founder and Chief Strategy Officer |
|---|---|
| Affiliation: | Ontopia |
| Email: | pepper@ontopia.net |
| By: | Lars Marius Garshol, Development Manager |
| Affiliation: | Ontopia |
| Email: | larsga@ontopia.net |
|
This paper describes some of the basic steps in applying topic maps in a real world application, a topic map-driven web portal of conference papers. It covers the tasks of collecting and examining source data, defining an ontology and populating a topic map. It discusses tools for automatically creating topic maps, with particular emphasis on how the synergies between topic maps and RDF can be exploited in the process of autogenerating topic maps from structured and semi-structured source data. It also provides an introduction to the concept of published subjects, describes how they are being applied in this project and details the benefits that they are expected to bring in both this and other projects.
Steve Pepper is the founder and Chief Strategy Officer of Ontopia, a company that provides topic map software, consulting, and training services.
Steve represents Norway on JTC1/SC34, the ISO committee responsible for the development of SGML and related standards, and is convenor of WG3 (Information Association), whose responsibilities include the HyTime and Topic Map standards. He is the editor of the XML Topic Map specification (XTM) and the author of numerous papers and presentations on topic map-related subjects, including the well-known TAO of Topic Maps.
A frequent speaker at SGML, XML, and knowledge management events around the world, Steve was for many years the author and maintainer of the Whirlwind Guide to SGML and XML tools. He also co-authored (with Charles Goldfarb and Chet Ensign) the SGML Buyer's Guide (Prentice-Hall, 1998).
Lars Marius Garshol is currently Development Manager at Ontopia, a leading topic map software vendor. He has been active in the XML and topic map communities as a speaker, consultant, open source developer, and technology creator for a number of years. He has worked with content management using SGML and XML since 1997, and using topic maps since 1999.
Lars Marius has also been responsible for adding Unicode support to the Opera web browser. His book on Definitive XML Application Development, was published by Prentice-Hall in its Charles Goldfarb series earlier this year. Lars Marius is one of the editors of the ISO Topic Map Query Language standard, and also co-editor of the Topic Map data model. He also chairs the OASIS GeoLang TC.
XML has achieved such enormous success in so incredibly short a space of time that it is hard to believe that it might all never have happened. And yet, without the invention of GML and the work that went into extending and developing it into SGML, there would have been no technical basis on which to define XML.[1] And without the conviction and devotion of SGML's early adherents, there would have been no community of experts and no body of experience on which the developers of XML could draw.
One of the chief contributors to the community building process was the Graphic Communications Association (GCA), originally part of the Printing Industries of America and now an independent organization, IDEAlliance. Legend has it that the first GCA conference on generalized markup took place in a converted church in Amsterdam in 1982. Following from that, the GCA started organizing annual conferences on both sides of the Atlantic, and later in both Asia and Australia. Over the past two decades more than 50 conferences have attracted untold numbers of participants to listen to the presentation of thousands of papers. Those papers have ranged from the simplest exposition of the basic principles of generalized markup, through case studies focusing on real-life experiences, to theoretical contributions that have advanced the field and, once in a while, represented major breakthroughs.
By the early '90s the availability of more robust SGML tools and authors' increased familiarity with them led the GCA to thinking that the time had come to eat its own dogfood. From 1994 authors were therefore first requested and later required to submit their papers marked up in SGML (and later in XML). A whole book could be written describing the resulting trials and tribulations, the teething problems and the lessons learned, but that is not the purpose of this paper. The point is that, thanks to this courageous (or foolhardy) decision, there now exists, in digital form, a vast body of knowledge about the domain of SGML, XML and related subjects, which can actually still be read rather easily – precisely because it is marked up in SGML or XML. It is that body of knowledge, and our attempts to make it available to today's information and knowledge management communities, that is the subject of this paper.
Not surprisingly, the technologies that we have used and describe in this paper are all based on XML, but XML alone was not enough. Fortunately, the development of SGML spawned the invention of the other technologies we needed, foremost among which are Topic Maps, XPath, XSLT and RDF.
While developing SGML in the early 1980's, Charles Goldfarb, himself a competent jazz pianist became intrigued by the idea of using SGML for a standardized representation of music. He was joined by Steve Newcomb, then a professor of music at the University of Florida, and a new ISO project was initiated for a Standard Music Description Language (SMDL) based on SGML. One of the major challenges would be to devise ways to capture the temporal aspect of music and to be able to represent synchronization.
Myth has it that news of the project came to the attention of information technologists in the CIA who turned up at an ISO committee meeting one day claiming that SMDL was just what they needed in order to represent, well, certain matters of interest to them – which also required the ability to represent timing and synchronization abstractly. Could the committee please add certain details drop all references to music, which would sound "inappropriate" in the Department of Defense! To cut a long story short, SMDL was put on ice while its more general parts were developed separately, and the result was HyTime ([ISO 10744]), an ambitious standard that sought to provide ways of addressing and linking to any kind of information, anywhere in time and space.[2]
HyTime was a major intellectual achievement and contained insights of immense value. But it also rapidly achieved the same reputation as Einstein's theory of relativity – of being totally impenetrable except to a handful of minds![3]
In order to help explain HyTime to the world, the GCA sponsored a project called "Conventions for the Application of HyTime" (CApH) whose goal was to come up with small subsets of HyTime, based on real use cases, that would be easier to understand and easier to implement than the full generality of HyTime itself. CaPH was driven principally by Newcomb and Michel Biezunski and one of the first real use cases they came up with was that of capturing the knowledge structures implicit in back-of-book indexes in order to able to automate merging and other processing of indexes. The original insights are due principally to Newcomb and the solution he and Biezunski devised was given the name "Topic Navigation Maps".[4]
What we now call Topic Maps went through several years of gestation, with the work migrating in 1996 to ISO's SGML committee under the editorship of Martin Bryan and Biezunski.[5] It was approved as an international standard in 1999 and published as [ISO 13250] in January 2000, by which time Newcomb was once more a driving force in its development. A year later, in March 2001, the "XML Topic Maps (XTM) Specification" ([Pepper 2001]) was published by an independent consortium called TopicMaps.Org, initiated by Newcomb and Biezunski and devoted to "developing the applicability of the topic map paradigm ... to the World Wide Web by leveraging the XML family of specifications."
RDF, the Resource Description Framework, was developed not by ISO but by the W3C and is grounded in artificial intelligence and formal logic. As its name implies, it was originally conceived as a framework for describing resources, in other words, a way of assigning metadata to documents and other information resources. However RDF, being based on formal logic, has far wider applicability and now forms one of the cornerstones of Tim Berners-Lee's vision for an artificially intelligent Semantic Web.[6]
RDF has been seen as a competitor to topic maps and indeed at a superficial level they are very similar in a number of respects.[7] Both attempt to alleviate the same general problem of the information tsunami by applying knowledge representation techniques to information management. Both define abstract models and interchange syntaxes based on XML and both have models that are simple and elegant at one level but extremely powerful at another: In topic maps, most things are topics (not just the "topics" themselves); in RDF, the value of a resource's property may itself be a resource which in turn has properties of its own.
However there are also significant differences, and attempts to achieve a unified model have so far met with little success. Recent work indicates that the differences are so significant that it makes more sense to look for synergies between the two paradigms than to try and unify them (or, more hopeless yet, decide which is "better"). The approach taken by the present authors – to focus on making RDF and topic maps interoperable – has proven very fruitful, as will be demonstrated in this paper.[8]
XSLT, or XSL Transformations, is another specification developed by the W3C that owes much to an earlier ISO standard, DSSSL (pronounced to rhyme with "whistle"). The purpose of DSSSL was to provide a standardized approach to the transformation and rendition of SGML documents. Since SGML documents (normally) contained no layout information, this needed to be expressed somehow in order for those documents to be formatted and that, in turn, required the ability to transform SGML documents from one form to another. DSSSL, which was principally the work of Sharon Adler, Anders Berglund and James Clark (the "ABC's of DSSSL"), formed the basis of the W3C's XSL, and XSLT, which we have used for the (relatively modest) purpose of rendering our source data as HTML in the XML Papers web application.
Another specification that came out of the development of DSSSL into XSL and XSLT was XPath, which is a simple yet powerful query language for XML. DSSSL had a set of operators for querying SGML documents known as SDQL, which used Scheme syntax. The first XSLT working draft took a similar approach by using an XML syntax to query XML documents. A major turning point in the development of XSLT was the replacement of this XML syntax by XPath. XPath has since proven to be one of the most important XML standards, and we have used it to extract information from the conference papers to build the topic map, as will be shown later.
But for the indefatigable work of Biezunski, who carried the flag with unfailing commitment, topic maps would have disappeared in the mid-1990's. Biezunski had a predilection for Venetian painters and would often use that domain for his shorter examples.[9] For his longer examples, he chose the proceedings of the conferences at which he was presenting his work, the first of which was the GCA's 1996 International HyTime Conference. In a paper presented at that conference his choice was explained as follows:
Why does a Topic Map fit Conference Proceedings?
The purpose of a Topic Map-based hyperdocument is to interconnect semantically heterogeneous information. Conference Proceedings seemed to us to be a good sample of a type of hyperdocument that is adapted to a Topic Map.
A Topic Map allows readers to navigate following topics that can appear in multiple documents. Rather than just being a simple term, a topic is a link that contains a title and is pointing to places in the documents where there are occurrences of this topic. These places, otherwise called anchors, can be grouped following various roles they play, and the anchor roles orient the navigation (e.g., definition, mention, example, etc.).
A Topic Map is functionally equivalent to multi-document indexes, glossaries, and thesauri. Topics are organized in types, each instance of a topic type has a title, and each occurrence of a given topic in a document is described including the semantics of the anchor role. ([Biezunski 1996])
The topic map of this conference was produced using software called EnLIGHTeN, developed by Biezunski himself, and the results were presented as a set of interlinked HTML pages that included the papers themselves, interspersed with links to the topics they covered, and a set of index pages for the topic types 'application', 'author', 'committee', 'company', 'concept', 'construct', 'ISO number', 'person', 'product', 'standard'. From an index of indexes one could navigate to a particular index (e.g., the index of standards) and select a subject of interest (e.g., the standard "Topic Navigation Maps"). This would present information about that subject, including typed links to other subjects (e.g., CD 13250 and CApH) and a list of mentions of that subject in the conference proceedings.[10]
Over the years Biezunski produced topic maps for most GCA conferences, and they were often included on the CD-ROM that accompanied the proceedings. Since the interchange syntax for topic maps still had not stabilized, he chose to publish HTML renditions of those topic maps rather than abstractions marked up in SGML and, for the same reason, the software he used was not able to export from its proprietary internal format to a standard interchange syntax. The formal abstractions of those topic maps are therefore no longer available.
The idea of using topic maps to improve access to conference proceedings, in particular those of the GCA, thus has a long and respectable pedigree. This paper describes how we have taken Biezunski's work to a new level, made possible by the experience we have gained in a number of topic map projects over the last few years, the publication of the ISO and XTM standards, and not least by the availability of a new generation of powerful topic map software.
It is fitting that our project should benefit IDEAlliance, the successor of the GCA, the organization that did so much to promote the technologies that made the project realisable, and that it should build on the pioneering work of Biezunski by focusing on the GCA's conference proceedings. Our primary goal in this paper is to provide a recipe for success when topic mapping "legacy data"[11], and to encourage new generations of topic map users to take the plunge and start applying the topic map paradigm in earnest.
The rest of this paper is concerned with the XML Papers project itself. We will briefly describe the goals of the project and then concentrate on the work that has actually been performed to date, paying special attention to methodologies, technologies and the lessons we have learned. The project is not yet complete, although a substantial topic map and application already exists that covers a dozen or so conferences. That application will be demonstrated during the presentation and the conference exhibition.
The idea of producing a "next generation" topic map of not just one GCA conference, but all of them was conceived by the present authors and embraced by IDEAlliance (the GCA's successor). The goal of the project is to collate (as much as possible of) a decade's papers on XML and related technologies, index them using topic maps, and make them accessible through a topic map-driven web portal.
A secondary goal is to provide input to the XMLvoc technical committee working on defining published subjects for the domain of XML. (The XMLvoc TC is one of several committees working under the auspices of OASIS in the area of published subjects, which are described later.)
Regarded simply, the task of designing and implementing a topic map application can be broken down into two basic steps:
Building the topic map
Building the application
Building a topic map involves a number of activities. In our case, since we were starting from a pre-existing set of information resources (the conference papers themselves). The first activity was to
collect and examine the data sources. Following that we had to
define an ontology and
choose an appropriate toolset. The major task was then to
populate the ontology, i.e. to construct the topic map itself. This involved discovering the topics, associations and occurrences as far as possible from the data, and also enriching the topic map manually. Both the definition of the ontology and its population were iterative processes, as will be explained. Finally, we had to
build the application that would use the resulting topic map to make the conference data available to users.
These are the essential tasks in any topic map application, but the amount of effort they involve varies tremendously from one application to another and will depend to a large extent on the nature of the legacy data. Sometimes defining the ontology is easy, because it already exists in some form, perhaps as a relational database schema or taxonomy. In other cases it requires serious analytical work with input from domain experts and can be a process that stretches over weeks or months. Sometimes a lot of effort needs to be put into evaluating tools in order to choose the best fit for the job. In our case this was a no-brainer since we had already developed most of the tools ourselves and wanted to use this project to make them even better.[12]
Usually the biggest challenge is populating the topic map. This can be done in a number of ways, which again depend on the nature of the legacy data. If the data is very well-structured and has clearly defined semantics, populating the topic map can be done 100% automatically. This is almost always the case with data originating from relational databases and may also be the case when the data has rich and consistent metadata, or is marked up using SGML or XML.
If the data is unstructured and has no useful metadata, the task is more complex. In such cases linguistic processing techniques can be used to get at topics, occurrences and sometimes even associations, but the results are rarely usable without some degree of quality assurance by a human, as we will show.
If the legacy data simply doesn't exist, or is in such a state that extracting its semantics automatically is like squeezing blood out of the proverbial stone, the bulk of the work has to be performed by humans. But just as in database applications, so too with topic maps: The long-term benefits can often justify the work involved in having humans input the data manually. It all depends on the application.
Never underestimate the difficulties involved in collecting the data! Even in an organization prescient enough to have used XML to preserve its information assets for future generations, do not assume that anyone has had time to store it in places where it can be easily located – or if they did, that it was sufficiently well-archived to survive the vagaries of reorganizations, takeovers and bankruptcies; that the owner will know what is the latest, definitive version (rather than a rendition, or one modified for some other purpose); that it will conform to one and the same DTD; or even that it will validate.
In our case, some of the source data had been distributed on CD-ROMs along with the printed proceedings, so we had something to start with, but it was just a fraction of what we knew ought to exist. Simply locating the rest proved to be a major task, and one that is still far from complete.[13]
We started with the data from the XML Europe conference held in Berlin in May 2001. Having previously written a number of papers ourselves we were fairly familiar with the DTD and knew that it had the following basic structure:
FRONT section, containing metadata about the paper (title, subtitle, abstract, keywords), the authors (names, job titles, email addresses), and the authors' affiliations (names postal details, homepage).
BODY section, containing the text of the paper itself, mostly marked up with layout information, but also including some keywords and bibliographical references.
REAR section, containing acknowledgements and bibliography.
The same structure has been used since the GCA started using SGML (although subtle changes have occurred during the years, as we later discovered). It is expressed in a DTD (or document type definition) which we will refer to as the gcapaper DTD.
When data is well-structured it usually contains a significant amount of semantics. Examining its schema (or, in the case of SGML and XML, its DTD) then provides immediate clues to the ontology, as we will show. But first, let us digress a little and explain what we mean by "ontology"?
The word "ontology" is used in a confusing number of different ways. The two basic (and most radically different) meanings come from the domains of philosophy and knowledge representation respectively.
In its original sense, in the domain of philosophy, "ontology" is defined as "The science or study of being; that department of metaphysics which relates to the being or essence of things, or to being in the abstract" (Shorter Oxford English Dictionary).
The term was taken over by the Artificial Intelligence community and one classic text book ([Russell 1995]) gives several definitions, including: "A particular theory of the nature of being or existence." John Sowa, in his highly recommended book, Knowledge Representation ([Sowa 2000]), provides the following, more precise definitions:
The subject of ontology is the study of the categories of things that exist or may exist in some domain. The product of such a study, called an ontology, is a catalog of the types of things that are assumed to exist in a domain of interest D from the perspective of a person who uses a language L for the purpose of talking about D. (p. 492)
Ontology: A classification of the types and subtypes of concepts and relations necessary to describe everything in the application domain. (p. 454)
This latter definition leads directly to our usage in the context of topic maps, where the basic building blocks are topics, associations and occurrences (a.k.a. the "TAO" of topic maps [14]). "Concepts" in Sowa's definition map to topics and "relations" map to associations (and also occurrences, a particular kind of association relating a topic to an information resource). Sowa's "types and subtypes" are thus our topic types, association types and occurrence types (and also association role types, although they can be ignored for the time being). Our operative definition of "ontology" in the context of topic maps is therefore:
The set of typing topics that is used within a given topic map, or that defines a class of topic maps.
To fully conform with Sowa's definition we should include the superclass-subclass relationships that exist between our typing topics (e.g. between "organization" and "company"), and it could also be argued that topics used as themes to define scopes also belong in the ontology, but for the purpose of this paper the definition given above will suffice.
Some people extend Sowa's definition of ontology to also include necessary constraints on the "types and subtypes" – for example the constraint that a relationship of type "employed by" must involve an "employer" and an "employee". (We prefer to keep the two terms separate: Constraints will be discussed briefly in connection with topic map schemas and validation, but for the most part we will concern ourselves only with ontologies as defined above.) Others use the terms "upper ontology" and "lower ontology", with the former corresponding more-or-less to our usage, and the latter denoting instances of the classes in the (upper) ontology.
Now that our usage of the term "ontology" has been established we can look at how an examination of the gcapaper DTD informs the design of the ontology.
A DTD is a schema for documents. It defines the "kinds of things" that exist in the document (principally element types and attribute), and also the rules that govern them: Content models determine the order and nesting of elements; attribute list definitions determine which elements have which attributes. Sometimes elements and attributes have purely layout significance but often they have semantic significance, that is, they represent, or at least indicate, things that exist outside the document, in the subject domain covered by the information in the document.
An examination of the gcapaper DTD reveals semantic element types like <author>, <affil(iation)>, <city>, <country>, <jobtitle>, <email>, <web> and <keyword>. These imply the existence of topic types such as 'author' and 'organization' (<affil> is described as "company, university, etc."), 'city', 'country' and 'term' (for keyword); and also occurrence types such as 'job title' and 'email' (for authors) and 'web site' (for organizations).
Relationships between these classes can be inferred from content models: Since <affil> is a sublement of <author>, the association type 'employs' can be inferred; likewise, since <city> and <country> are sibling elements, the 'contains' (or 'located in') association type can be inferred. And so it goes on. Like a database schema, a semantically rich DTD (as opposed to one that consists solely of layout-oriented element types) can be a very fruitful source of ontological (or 'typing') topics in a topic map.
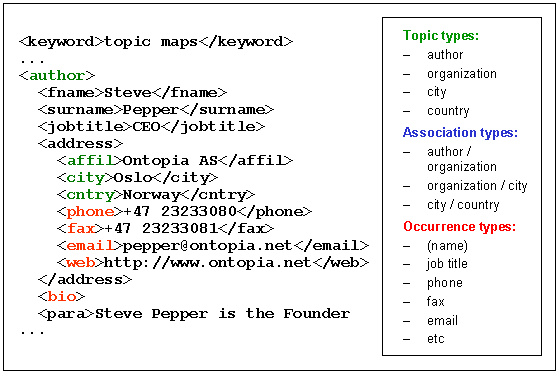
Using the approach outlined above one can quickly arrived at a basic ontology consisting of the following types:
TOPIC TYPES: Author, City, Company, Country, Province, State, Term
ASSOCIATION TYPES: Contains, Employs, Site of
In this first prototype we did not bother with occurrences like 'job title', 'email' and 'web site'; instead we contented ourselves with the single occurrence type 'mentions' to link papers to the topics they had given rise to. (In fact, the ontology was actually lifted wholesale, without further thought, from the topic map on the CD-ROM of the previous conference, XML 2000 in Washington DC.)
Once the ontology was defined it was a simple matter to write a Python script that processed the documents and populated the topic map using the API of our topic map engine. The script ran through each paper in turn, looking for certain element types. From an <author> element a topic of type 'author' was inferred and its base name was constructed from the content of the <fname> and <surname> elements. A <city> element containing the string "Oslo" resulted in a topic of type 'city' whose base name was "Oslo"; a <country> element containing "Norway" gave rise to a topic of type 'country' with the name "Norway"; and the fact that the two elements were siblings led to the creation of an association of type 'contains' between the respective topics.
Subject identifiers were used in order to establish identity and ensure that multiple mentions of the same subject resulted in a single topic. They were constructed by normalizing the name of the topic and creating a temporary URI that included the topic type. Thus, "Oslo" became "http://psi.ontopia.net/xmlconf/city/oslo". This allowed us to merge correctly on the basis of names without risking the kind of undesirable results that merging based on the topic naming constraint often leads to. (Merging still wasn't perfect, however. For example, "Greg Fitzpatrick" and "Greg A. Fitzpatrick" were still two different topics, as were "empolis UK" and "empolis U.K.". These problems would be addressed later.)
In this way it was possible to construct a topic map of over 3,000 TAOs (topics, associations and occurrences – a unit of measurement for the size of a topic map) completely automatically. It was a little rough around the edges, admittedly, but for a first attempt it wasn't bad. And it encouraged us to take the application a number of steps further at the next conference.
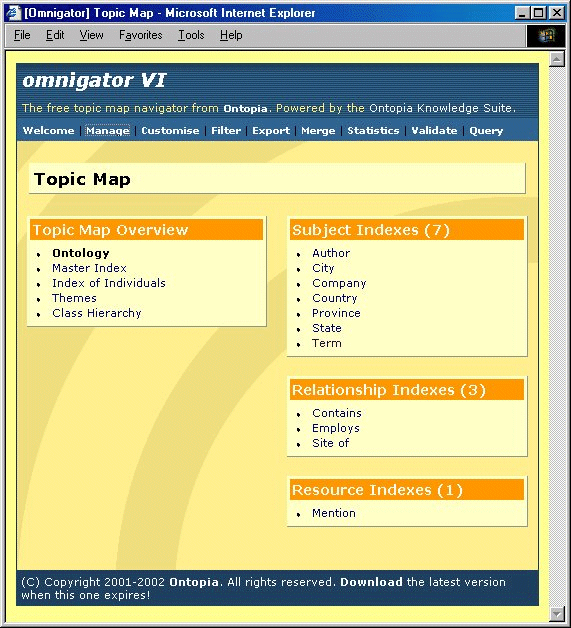
In order to explain the sloppiness of our first cut at a conference proceedings topic map, it should be made clear that at this point we had absolutely no plans to embark upon a major project. The truth of the matter is that one of the authors (who shall remain nameless) sat down in an idle moment at the conference to see how quickly he could hack the contents of the CD-ROM into a form that could be loaded into Ontopia's topic map browser, the Omnigator. He claims that his Python script took about two hours to write and three minutes to run, and that the resulting topic map took five seconds to load into the Omnigator. While fairly impressive, this does explain why the results left somewhat to be desired.
For our second, more serious attempt, we made three changes: to the ontology, to the software, and to the kind of processing we were performing to generate the topic map.
The most important change to the ontology was the decision to consider the papers themselves as topics, rather than simply as information resources connected to other topics via occurrences. This brought a number of benefits. First of all, it became possible to give the papers names, which we could then display (instead of meaningless URIs), from their own pages and from those of related topics.
Secondly, it enabled us to express the relationships between the papers and the other topics more appropriately. In the first version, because the papers had been made occurrences of the topics they had given rise to, they ended up being connected directly to organizations, cities and countries, which didn't make a lot of sense. Now that papers were topics it became clear that the only meaningful associations that involved them were those with authors and terms (keywords).
A small number of other improvements were also made to the ontology, including the addition of occurrence types for 'home page', 'email' and 'source' (since papers were now topics, the latter was necessary in order to locate the contents of the papers). Apart from allowing us to include more useful information in the topic map, we could also improve the merging of organizations and persons that had multiple names by performing merging on the basis of web and email addresses in addition to names (thus "ActiveState" and "ActiveState Corporation" were regarded as the same topic because they had the same web address "http://www.activestate.com").
The Python script that had been quickly hacked for the previous conference had been useful in helping us understand what was possible and we could have continued along that route. However, we wanted to use this opportunity to create something that could be reused in other projects – preferably by non-programmers.
Ontopia had been thinking about approaches to the automatic generation of topic maps for some time and Kal Ahmed had come up with MDF, the Metadata Processing Framework, which he presented together with one of the authors at a tutorial during the Knowledge Technologies 2001 conference in Austin, Texas. The architecture of the MDF is based on two important insights:
(1) Many of the operations performed on legacy data when generating topic maps are simple manipulations of flat blocks of property/value pairs. This is especially true when extracting topics and associations from metadata.
(2) There are a large number of common operations, including directory scanning, extracting property/value pairs from XML, converting data types, normalising values, splitting single values into multiple values, traversing HTTP links, etc. However, the exact operations required and the order in which they should be performed varies for each application.
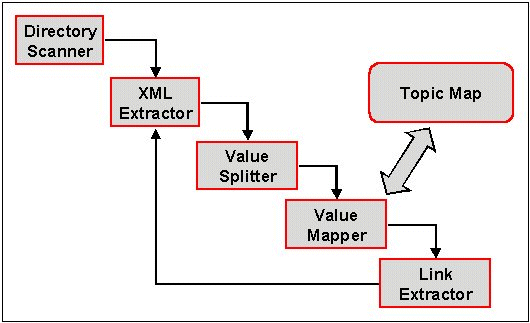
To ensure maximum flexibility, the MDF was designed as a set of reusable processing modules that could be chained together in any order. The processing chain, and any parameters that needed to be passed to the individual modules, was defined in an XML configuration file. Each module received a metadata set from the upstream module and either modified it or used it to determine how to query or update some external data source, and then passed on one or more metadata sets to the downstream modules. A special module, TM-mapper, mapped the property/value pairs to topic map constructs using Ontopia's topic map engine and the result was written out as XTM.
The MDF was demonstrated to work well with three quite different data sources – MP3 files, Word documents and the contents of an XML database – and topic maps were created from each of these. A typical processing chain is shown in [xref: ].
The MDF quite obviously represented a more general (and therefore inherently better) approach to topic map autogeneration than the original Python script, but it wasn't general enough. The main weakness was the data model, which essentially consisted of collections of property-value pairs. This meant that relationships could not be represented directly, which made it awkward for creating topic maps. This also caused a second problem, which was that the mapping from the MDF data model to topic maps became complex and inflexible. A related problem was that the passing of value sets between modules was very complex and made for chains that were hard to debug.
To counter these weaknesses it was decided to use RDF as the data model for the framework. That is, the processsing would build an RDF model during processing that would be accessible from any module, and to integrate an RDF engine with query capabilities.
RDF seemed to be the logical choice; after all, it is essentially a way of expressing property/value pairs, which was just what we needed, but it does so using triples, not pairs, which means that all the necessary information (property, value and the thing the property applies to, the property "owner") are available in a single data structure. In MDF, the property "owners" were always implicitly represented by each property/value set. However, if property/value pairs were going to be hanging around throughout the full processing cycle (as we wanted them to), it would be crucial to have some unambiguous way of identifying their owners. RDF triples gave us that out of the box.
There were other reasons for choosing RDF as well. First of all, it could handle complex metadata values, not just simple property/value pairs. For example, representing relationships became much easier. Secondly, we could use existing tools instead of writing our own. (This would be especially important in applications where the RDF model became too large to be held in memory and would need to be queried while in a persistent store.) Thirdly, this would give us an excellent way of understanding exactly how RDF and topic maps fitted together, and how to map the one to the other in the most appropriate way.
The result was the MapMaker[sup: TM] toolkit, which was first presented at Knowledge Technologies 2002 in Seattle. That presentation ([Pepper 2002a]), which was part of a joint session with Eric Freese covering many aspects of topic map autogeneration, showed how to use RDF to generate a topic map from the contents of a USENET news group. The data consisted of a set of archive files, each containing a number of news postings. Each news posting had a header, consisting of metadata conforming to RFC-822 ([Crooker 1982]), and content.[15] The task at hand was to:
The diagram in [xref: ] shows how it was done.
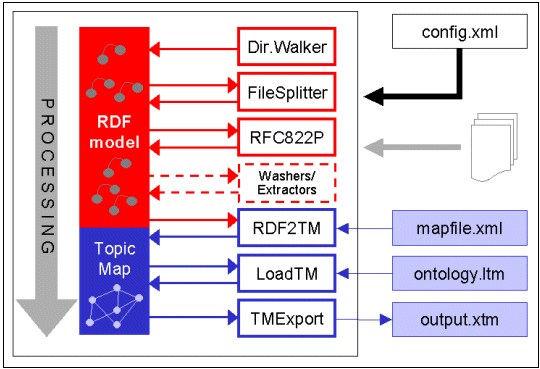
Processing proceeds from top to bottom and is controlled by a configuration file (config.xml) which specifies which modules to call, which order to call them in, which parameters they require, and what RDF statements they should create. As each module is called an RDF model is constructed. Modules may augment or modify the model, which becomes richer and richer as processing continues and more semantics are extracted from the data.
The following simple example shows how the directory-walker module is instructed to find the set of files in the file system that correspond to archives from the XML 2001 conference, and to create RDF statements whose property (or predicate) is a URI representing the "presented at" relation and whose value (or object) is a URI representing the concept "XML 2001"; the "owners" (or subjects) do not have to be specified because the directory-walker module knows to represent them using the URI of the files matching the pattern text*.txt found while walking the directory tree starting at the given location:
<directory-walker
directory = "newsgroup/src"
pattern = "*text*.txt">
<out
property = "rdf:type"
value = "http://psi.ontopia.net/newsgroup/#source-file"/>
</directory-walker>
The output of this module is a set of RDF triples that state which "things", represented by URIs pointing to files on the file system, have the 'type' property whose value is the URI representing the concept "source-file". These statements go into an RDF model which is kept in memory. The next module, file-splitter, uses these RDF statements to find each archive in turn and splits the archives into separate files, one for each "story". For each story, it creates a new RDF statement:
<file-splitter
separator = " Article: "
out-directory = "newsgroup/split"
filename = "story-%s.txt">
<in seek-property = "rdf:type"
seek-value = "http://psi.ontopia.net/newsgroup/#source-file"/>
<out property = "rdf:type"
value = "http://psi.ontopia.net/newsgroup/#story"/>
</file-splitter>
Subsequent modules that perform further processing are the rfc822-parser (for parsing the header fields), regexp-grouper, tokenizer, identity-maker, etc. As each module performs its task, the RDF model is enriched, until the point is reached where every single drop of semantics has been squeezed out of the data. Now the "mess" of RDF triples is mapped into a tidy and highly interconnected topic map structure; a small pre-existing topic map containing the ontology (i.e., the typing topics) is merged in; and the result is exported to XTM syntax.
The mapping from RDF to topic maps – in some ways the most interesting part of the whole process – is performed according to the principles first described in [Garshol 2001b]. The basic tenet of our approach is that, in theory, RDF predicates can be mapped to any one of five very different constructs in topic maps, namely: names, associations, occurrences, subject indicators or subject addresses.[16] However, without knowledge of the underlying semantics of the predicate it is not possible to know what is the most appropriate kind of construct to map any given RDF predicate to. For this reason, generic mappings will (in the general case) result in inappropriate, and thus suboptimal, mappings. Really useful mappings require knowledge of the ontology and are therefore best defined at the level of the schema.
Once this is realized it is a simple task to create rules that describe the optimal mapping for a given RDF model (which may or may not be described in an RDF schema) to a particular topic map ontology. In the first generation of the MapMaker such mappings were expressed using our own XML language. These days we are using RDF instead.
This section has gone into some detail in describing the architecture of the MapMaker toolkit because understanding the MapMaker is essential to understanding the ease with which we have been able to take the rough results from our first foray and steadily refine them, while at the same time building a toolkit that can be leveraged repeatedly in almost every topic map project.
Two of the improvements we made between May 2001 and December 2001 were to refine our ontology (in particular, by regarding papers as topics rather than occurrences) and to redesign our toolkit. The third was to introduce scanning.
As we have already seen, the gcapaper DTD (and its variants) includes an element type that allows authors to attach keywords to their papers. Keywords are important because they are intended to capture the "aboutness" of the information and thus provide the most suitable entry point to it (for example, a user will typically be looking for information "about", say, "RDF" and "topic maps", rather than a paper "written by" some particular person). Unfortunately, our experience was that the keywords available in the XML data were almost unusable.
The problem, of course, is that authors use keywords very inconsistently. Some don't use them at all, while others provide dozens. Most don't put a lot of thought into which terms they choose; some place all their keywords in a single <keyword> element (instead of using multiple elements as intended); and others have their own, very strange notion of just what a keyword is. Some of our particular favourite "keywords" were:
"authors can be easily trained (and trusted) to use MS-Word named styles to mark up their content"
"UDDI (Universal Description, Discovery and Integration) is a sweeping industry initiative. The UDDI Standard creates a platform-independent, open framework for describing services, discovering businesses, and integrating business services using the Internet."
"descriptive, procedural, retrospective, prospective, proleptic, metaleptic markup"
Even when authors do put real effort into supplying a limited number of sensible keywords, they have no way of knowing whether the terms they choose are the same as those used by others writing "about" the same subject. For that, they would need access to a controlled vocabulary of terms in the domain of XML and related technologies, which at that time did not yet exist. (IDEAlliance has recently introduced such a vocabulary and we hope that our work can be used to improve it.)
As a result, the findability due to keywords in our application was very limited. We therefore decided to disregard the assertions that authors were making about their papers and rather use their keywords as input to what would be a decidedly "uncontrolled vocabulary". That vocabulary was then used as input to a scanner module in MapMaker, which trawled the contents of all the papers and produced associations between papers and the terms they mention. For good measure we added the names of authors and organizations to the uncontrolled vocabulary and included them in the scanning (leading to rivalry within Ontopia as to who had been mentioned most![17]).
The result was a marked improvement in consistency and, to some extent, also findability. The distribution of keywords by paper was much more even, and any paper that mentioned a particular technology was now linked to that topic, regardless of whether the author had included it as a keyword or not. However, the initial scanning algorithm was rather primitive: It did not perform stemming (and thus treated for example "Topic Maps" and "Topic Map" as separate topics), and it made no attempt to weight the importance of individual terms to papers. These issues would be addressed later.
We were also dissatisfied with the handling of keywords for a number of other reasons: First of all, the index of keywords was simply too long (it contained 559 entries). It was also very heterogeneous, as the following excerpt demonstrates:
As can be seen, keywords cover a multitude of sins. In addition, they are quite arbitrary: A lot of interesting terms were not being picked up, simply because no-one happened to have supplied them as keywords (was there really nothing about "addressing" or "aerospace" in this material?); and many less than interesting terms were being included (what on earth was "adjacent"???!). Lastly, it was impossible to navigate among keywords. There were clearly many interesting relationships between the terms (e.g., between "graphics", "SVG" and "WebCGM", or between "IFX" and "financial information"). We would have liked to be able to use these relationships for navigation, but this was not possible because they were not captured in the topic map.
In short: The ontology needed to be beefed up, some associations needed to be created manually, and the scanner needed better input. The time had come to integrate this work with that being carried out in the OASIS XML Vocabulary Technical Committee.
The first two generations of the XML Papers topic map had been almost entirely data-driven. The ontology was derived directly from the underlying schema (i.e., the DTD) and, with the exception of the use of scanning, the instantiation of the ontology (i.e., the population of the topic map) had been based entirely on metadata available in the data. The results were surprisingly good, given how little work it had taken, but we were approaching the limits of what could be achieved through automated processing. The problem was simply that our source data was insufficiently descriptive. We needed some other, richer sources, and the first place we turned to was the XMLvoc committee in OASIS.
After the delivery of XTM 1.0 in March 2001, TopicMaps.Org and the ISO topic map committee agreed on a division of labour, whereby ISO would retain responsibility for core standards development, while TopicMaps.Org would focus on user community issues. Two new work items were approved by ISO, for TMQL (Topic Map Query Language) and TMCL (Topic Map Constraint Language), and work was begun on clarifying and reformulating the topic map data model.[18] TopicMaps.Org became a member section of OASIS and decided to put its initial efforts into promoting the concept of published subjects. Three technical committees were established:[19]
PubSubj, whose task was to formulate requirements and recommendations for the definition and use of published subjects
GeoLang, charged with producing sets of published subjects for the domain of geography and language, based on those published as part of the XTM 1.0 Specification
XMLvoc, responsible for defining an ontology suitable for describing technologies and standards makers in the XML domain
The last of these was engaged in work directly related to the XML Papers project. Before discussing it, however, a brief digression is required to explain the concept of published subjects.
Put simply, published subjects provide a mechanism whereby computers (and also humans, in interaction with computers) can know when they are talking about the same thing. In other words, they establish the identity of subjects of discourse. The importance of establishing identity cannot be overstated; without it, there can be no communication between humans and no interoperability between applications.
In discourse between humans, identity is established by a complex process based on the use of names in contexts. Context is important because the same name may be used for different subjects (we call this the "homonym problem") and because the same subject may have more than one name (the "synonym problem").[20] Sometimes the context is clear enough and communication is established immediately; in other cases a complex process of negotiation takes places until a common context is established: "Oh, you mean Paris, Texas; not Paris, France?" Or (overheard in Dallas, Texas): "Oh, there's a Paris in France, too?".
As we know, computers are not as smart as humans. They usually cannot deal with fuzziness and need to have identity established more precisely. On the Web, identity is established through the use of URIs to provide the address of the subject. Thus "Get me Steve's TAO article" translates to the following being sent to www.ontopia.net:
GET /topicmaps/materials/tao.html HTTP/1.0
This works fine with subjects that are information resources (as in this case), but not at all well with other subjects. For example, if we want to refer to the author of the above mentioned article ("Steve"), how do we do it? We could do it using his email address as a URI ("mailto:pepper@ontopia.net") ... but what happens then if we want to talk about Steve's email address? Wouldn't that have the same URI, and wouldn't that result in Steve and his email address – two quite different subjects – becoming conflated?
It is problems such as this that published subjects are designed to address. In the topic map paradigm, a distinction is made between addressable subjects (i.e., information resources, such as Ontopia's home page) and non-addressable subjects (everything that is not directly addressable, including Steve, Lars Marius, and Ontopia itself). The identity of an addressable subject is established easily and unambiguously using its subject address (e.g. "http://www.ontopia.net" for Ontopia's home page). The identity of a non-addressable subject is established using subject indicators.
A subject indicator is simply a resource that in some way conveys an indication of the identity of a subject to a human. For example, in the case of "Ontopia" it could be an HTML page explaining that Ontopia is a company located in Norway that provides topic map technology and services. Any human reading that page would then know that the Ontopia in question was not, say, an online computer game (which actually existed in Tel Aviv up until a few months ago). Of course, that HTML page is only of use to humans; a computer would be none the wiser. However, since it is a resource, the HTML page has an address – a URI, for example "http://www.ontopia.net/about" – and that URI can be used by a computer, because it is a string that can be compared with other strings. The URI of a subject indicator is called a subject identifier and it is used by computers to establish whether two subjects are the same or not.
Note that the same URI can be used as both a subject address and subject indicator – for different subjects. For example, for the HTML page mentioned above, the URI "http://www.ontopia.net/about" would be both the subject address of the Ontopia "About" page, and the subject identifier of Ontopia itself. Anyone can declare a subject indicator for any subject they want. In addition, a single subject can also have multiple subject indicators. The significance of these features will be brought out below.
The distinction between addressable and non-addressable subjects is one of many important insights that the topic map paradigm brings to information and knowledge management, and forms the basis of the notion of published subjects, which we believe can solve the problem of identity as it exists today, in particular on the World Wide Web.
As we have noted, subject indicators/identifiers can be declared by anyone, and we have already used them in this paper: The URIs used in the examples in section 3.2.2 to identify the classes to which our USENET source files ("http://psi.ontopia.net/newsgroup/#source-file") and the individual stories ("http://psi.ontopia.net/newsgroup/#story") belonged are, in fact, subject identifiers. They were used to establish the identity of certain subjects (in this case, classes of things) such that different parts of the MapMaker application could use them appropriately. In theory, anyone could use those same subject identifiers to denote the same subjects and our applications would immediately be interoperable.
But there is one small problem: Nobody else knows that those subject identifiers exist and even if they did, they couldn't be sure of their precise meaning because the URIs don't resolve to human-interpretable information resources – for the simple reason that we didn't bother to create subject indicators for them: That wasn't necessary for our purpose. But what if we had been creating subject identifiers for ourselves, the authors, in order to ensure that anyone (bless them) wanting to talk about the subjects Steve Pepper and Lars Marius Garshol had a well-established and commonly accepted way of referring to us? In that case we would have to publish the URIs (so the world would know about them) and create subject indicators for them (so that humans wanting to use them, for example in their topic maps or RDF applications, could be sure that they referred to THE Steve Pepper and THE Lars Marius Garshol and not some imposters!).
This is the essence of the concept of published subjects: That someone, somewhere, of greater or lesser authority, has decided to create subject identifiers (and corresponding subject indicators) for a set of subjects and publish them, in the hope or expectation (or just on the off chance) that others will use them when they need to refer to those subjects. When subjects are published in this way, with the intent that they be used by others, we called them "published subjects" and we talk of "PSI sets", where the acronym "PSI" significantly has two expansions – "published subject indicator" and "published subject identifier" – thus neatly reflecting the duality of published subjects: the human interpretable aspect (subject indicators) and the computer processable aspect (subject identifiers).
Whether a PSI set actually gets used will depend on a number of factors: Whether anyone has a use for it (of course), whether alternatives exist elsewhere (remember, anyone can create a PSI set) and, more importantly, whether the publisher is deemed sufficiently trustworthy. The issue of trust is important because one of the main reasons for using PSIs is to ensure interoperability between applications, including applications that do not yet exist. The value of using PSIs increases almost proportionately with their stability and breadth of adoption: Choose a set of PSIs that disappears from the face of the earth after three months, or that no-one else uses (because there is a more stable alternative), and the interoperability benefits are less than they might have been. Knowing who has published a PSI is thus (almost) as important as knowing the PSI itself.
Having said that, it is important to be aware that all is not lost, even if the PSIs one has chosen to use become outdated, since it is always possible to create a mapping from a defunct PSI to an extant one. To illustrate this important point, consider the case of PSIs for countries and languages. The XTM 1.0 specification included a set of published subjects for each of these, with PSIs such as http://www.topicmaps.org/xtm/1.0/language.xtm#en (for English). Those PSIs have been widely used in topic maps created during the past two years, but now the PSI sets are being revised in order to rectify certain errors and ensure conformance with the recommendations and requirements being developed by the OASIS Published Subjects TC. For various reasons (including uncertainty about the status of the topicmaps.org domain), new subject identifiers are likely to be defined, e.g. http://psi.oasis-open.org/geolang/iso639/#eng.
Will this impair the interoperability of all existing topic maps? The answer is no – because the TC will provide a machine-readable mapping table for use with topic maps using the outdated PSIs. In fact, one of the forms in which that table will be distributed will be as a topic map consisting solely of topics like the following:
<topic id="eng">
<subjectIdentity>
<subjectIndicatorRef
xlink:href="http://psi.oasis-open.org/geolang/iso639/#eng"/>
<subjectIndicatorRef
xlink:href="http://www.topicmaps.org/xtm/1.0/language.xtm#en"/>
</subjectIdentity>
</topic>
Simply merging this topic map with the "legacy" topic map (a simple operation for any conforming topic map application) will provide all language and country topics with an additional set of subject identifiers and ensure their future interoperability.
Published subjects accomplish what neither URLs or URNs have been able to do in terms of establishing identity in a robust and scalable manner. Whereas URLs can only establish the identity of information resources, PSIs can establish the identity of anything at all. And whereas URNs are strictly controlled by the IETF (and thus little used) and have no simple resolution mechanism (and are therefore hard to interpret), PSIs can be defined by anyone and resolve simply to human interpretable subject indicators. We believe that an evolutionary process will take place during which increasingly stable and trustworthy PSI sets will develop for more and more of the subjects about which humans and applications need to discourse: "Survival of the fittest" will in this context mean survival of the most stable and trustworthy. This will have immense benefits in terms of interoperability, especially in areas such as web services and the Semantic Web.
In order to promote such a development, members of TopicMaps.Org are working with OASIS to define both guidelines for the publication and use of PSIs, and actual sets of PSIs. Communities of interest are being encouraged to join in this effort by establishing technical committees to define their own PSI sets. One such is the XML community itself, whose needs are being catered for by the XML Vocabulary TC. The statement of purpose of this committee begins as follows:
This Technical Committee will define a vocabulary for the domain of XML standards and technologies. The vocabulary will provide a reference set of topics, topic types, and association types that will enable common access layers – and thus improved findability – for all types of information relating to XML, related standards, and the XML community. The vocabulary items will be defined as Published Subjects, following the recommendations of the OASIS Topic Maps Published Subjects Technical Committee.
The establishment of the vocabulary as a set of Published Subjects will enable providers of information about XML to create topic maps, which will become robustly mergeable and interoperational with other XML-related topic maps. This in turn will open up the possibility of collaboratively developing overarching indexes that improve accessibility to all aspects of XML, its related specifications, the community that uses it, the tools that support it, and those that provide services and expertise around it. The use of the defined Published Subjects is by no means restricted to topic maps: for example, they could be used in RDF to identify appropriate classes and properties of resources. ([XMLvoc 2002])
The XMLvoc TC has not finished its work, but it has already sketched a set of PSIs for concept and relationship types that we were able to use for the XML Papers application. The most important of these relate to documents, technologies, people, organizations and standards activities, all of which are organized into taxonomies. The draft taxonomy for formal languages (a subclass of technologies) is as follows (note that the PSIs are as yet completely unofficial):
Proposed taxonomy of formal languages:
Some progress has also been made on defining the kinds of relationships that can exist between these classes of things, including the following:
Proposed association types:
This provided a useful starting point for us to be able to classify the keywords used in our conference papers, to express the relationships between them, and to provide more intuitive navigation paths between many of the topics. There was just one slight problem: The only thing XMLvoc gave us was the classes. We now had to assign instances to those classes, and that could only be done manually.
Everything we had accomplished up to this point had been done using automated routines, but now, finally, we had to stoop to doing manual labour. We felt that it would repay the investment in terms of enabling more intuitive navigation and providing useful feedback to the XMLvoc committee, and it might also be reusable in other XML-related applications, of which there could be many (think only of XML.org and the XML Cover Pages).
The central focus of XML conferences is, of course, XML technologies, so we decided to start with these and let our association types lead us to all relevant related subjects. Casting around on the 'net we found a number of useful starting points, foremost among them [ZapThink 2002], an overview of XML markup languages published as a poster in PDF format by ZapThink, and [Wilde 2002], a web site containing a web glossary maintained by Erik Wilde. The ZapThink poster gave us the names and acronyms of over 135 markup languages, ranging from XLink to NewsML to ADML (Astronomical Dataset Markup Language), and also a basic categorization by industry or application area. Erik Wilde's glossary supplemented this with terms which he classified as APIs, companies, concepts, formats, hardware interfaces, image formats, organizations, products, programming languages, protocols, and the like. Although we didn't use Erik's classification scheme, we were very grateful for his instances, which saved us a lot of trouble.
In addition to the above, we randomly added a few subjects of our own, such as HyTime (which everyone else appeared to have forgotten!), and some interesting concepts from the domain of SGML and XML, such as LINK and CONCUR (remember those SGML features?), ANY and EMPTY (interesting kinds of elements about which much has been written), and a few other pet loves and hates.
Another source of useful subjects that was readily available was the Free XML Tools website ([Garshol 1998]), which one of the authors had maintained for several years and even published as a topic map. Here was both a useful categorization system for XML tools (which itself was based on [Pepper 1992] and [Goldfarb 1998]) and a comprehensive list of all the free ones, their originators and the standards that they supported. Instead of just copying parts, we decided to incorporate it wholesale as a topic map, but before we could do that, we had a job to do furnishing it with subject identifiers that were aligned with ours.
Having captured all of these new subjects and added them to the seed topic map, we were able to provide our scanner with much better input. The combination of subjects that we had identified "up front" and those specified as keywords in the papers was substantially more exhaustive and representative. The results were impressive, especially in terms of the enhanced navigational possibilities that emerged. These were further improved by manually creating associations, in particular those between markup languages and the organizations responsible for them.

There were still weaknesses, however, chief among which were:
The average paper was now related to even more keywords, without regard to relevance weighting.
Some keywords were getting incredible numbers of hits. (The worst culprit turned out to be ANY, closely followed by LINK and EMPTY. The scanner was obviously going to have to be taught the meaning of case sensitivity!)
A few keywords were subject to the homonym problem. (For example, there is a free XML tool called "Markup". Guess how many hits that one was getting!)
Inflected forms of names were being treated as different subjects. (Thus, "topic maps", "topic map" and "topic mapping" were regarded as three distinct subjects. Although that might be correct in some circumstances, for the purpose of our application it would be better to regard them as different ways of naming the same subject.)
It was clearly not enough to improve the input to the scanner. We had to improve the scanner itself.
Four improvements were made to the keyword scanner. First of all, instead of performing indiscriminate case insensitive scanning, the following rules were applied:
All terms in our controlled vocabulary (i.e., the populated topic map used as input to the scanner) were stored in lower case (e.g., "topic maps") unless they were proper names, acronyms or name tokens, in which case the correct combination of upper and lower case letters was used (e.g., "Markup" (the tool), "ebXML", "ANY").
Case insensitive scanning should be performed for terms from the controlled vocabulary, unless the terms contained one or more upper case letters, in which case sensitivity should be used.
Case sensitive scanning should be performed for terms from the uncontrolled vocabulary (i.e., those found as keywords in the data), unless a case insensitive match could be found with a term from the controlled vocabulary, in which case they would be ignored.
These simple rules seem to have removed our case sensitivity problems in one fell sweep (and ANY is no longer the most talked about subject!).
Secondly, we introduced a primitive stemming capability to cater for singular and plural forms:
For every lower case term from the controlled vocabulary that ends in "s" or "ies", scanning is also performed for the singular form. Thus "topic maps" also produces matches on "topic map".
For every lower case term from the controlled vocabulary that does not end in an "s", scanning is also performed for the plural form with an appended "s" (or "ies" if the term ends with a "y"). Thus "hypergraph" also produces matches on "hypergraphs", and "wireless technology" also produces matches on "wireless technologies".
Once again, this seems to have solved almost all our problems with inflected forms. The few remaining "gotchas" can be catered for using multiple base names, as described in the discussion of "concept clusters" below.
Thirdly, we introduced a weighting algorithm that works as follows:
We define three levels of "aboutness": primary mentions, secondary mentions and tertiary mentions (which happily get sorted in the correct order!)
Primary mentions are defined as mentions of terms in the title of the paper or its keywords.
Secondary mentions are defined as terms mentioned in the abstract of the paper or its subheadings that are not also primary mentions.
Tertiary mentions are defined as terms mentioned in the body of the paper that are not also either primary or secondary mentions.
We have considered counting the number of mentions (especially in the body) in order to further improve weightings but have so far not done so, because the results of the algorithm described above seemed to be more than good enough. For example, the article Topic maps, RDF, DAML, OIL ([Garshol 2001b]) is categorized as being about the following:
Major topics (primary mentions): DAML, OIL, RDF, topic maps
Minor topics (secondary mentions): knowledge management
Other topics (tertiary mentions): C, content management, DAML+OIL, defense, DTD, HyTime, LTM, Markup, metadata, PICS, Python, RDF-S, search & querying, tolog, TMQL, XLink, XTM
Finally, we added stemming of organization names, stripping trailing words like "Corp.", "Ltd", "A/S", etc. in order to cater for inconsistencies in the ways in which authors specified the names of their affiliations.
We are currently investigating whether the use of advanced natural language processing technology would yield significant improvements on the results we have obtained ourselves. At the moment, the conclusion seems to be that they do not – at least not significant enough to justify the price of some of them!
In addition to keyword scanning, we have also introduce scanning of references to papers. Many of the papers presented at the GCA's conferences cite papers that have been presented previously. This allows us to construct associations of type 'citation' and provide additional navigation paths of interest to the user. (See the example in the screen shot of the Navigator applicaton below.)
We had reached the limit of metadata extraction from the source data, but it was still possible to enrich the topic map by extracting portions of the content, in particular abstracts and author biographies. These were captured as two more occurrence types on the topic types 'paper' and 'person' respectively. This allowed us to provide more interesting information in the browser interface, as shown in the previous screenshot. But it also brought us a new challenge.
By this time we had gathered more source data and were now generating topic maps that covered the following ten conferences:
The problem that immediately became apparent was due to the fact that the same person might have presented papers at more than one conference. In itself this wasn't a problem, except that one person would now have multiple affiliations, email addresses and bios, many of which might have changed from one conference to another. Fortunately the solution was ready to hand, in the guise of "scope", the topic map construct used to attach information about contextual validity to assertions. Papers were already associated with conferences (the 'conference' topic type had been introduced when we went multi-conference), and conferences were associated with dates, so we could simply use the date topics to scope assertions derived from papers presented at different conferences, as follows:
<topic id="id11445">
<instanceOf><topicRef xlink:href="#person"/></instanceOf>
<subjectIdentity>
<subjectIndicatorRef
xlink:href="http://psi.ontopia.net/xmlconf/authors/steve-pepper"/>
<subjectIndicatorRef
xlink:href="mailto:pepper@ontopia.net"/>
</subjectIdentity>
<baseName>
<baseNameString>Steve Pepper</baseNameString>
</baseName>
<occurrence>
<instanceOf><topicRef xlink:href="#biography"/></instanceOf>
<scope><topicRef xlink:href="#may2002"/></scope>
<resourceData>Steve Pepper is the founder and Chief Strategy Officer
at Ontopia...</resourceData>
</occurrence>
<occurrence>
<instanceOf><topicRef xlink:href="#biography"/></instanceOf>
<scope><topicRef xlink:href="#may1999"/></scope>
<resourceData>Steve Pepper is the Senior Information Architect
at STEP Infotek...</resourceData>
</occurrence>
<!-- etc. -->
</topic>
Note the use of <scope> elements on the occurrences, providing information about the context in which the bios of Steve Pepper are considered valid. The same was done with 'email' and 'job title' occurrences, and also 'employed by' associations. This enabled us to display the information that was relevant at the time of the conference, and also to display the most up-to-date information available.
Since the seed topic map (i.e., the extended and populated XMLvoc topic map) was being maintained by hand and had grown considerably, it became necessary it became necessary to ensure that it remained internally consistent. For example, we wanted to ensure that every markup language was associated with a domain (either a vertical industry or a horizontal application domain) and with the organization responsible for maintaining it. Since the topic map standard itself has no facilities for expressing constraints, and the work on Topic Map Constraint Language (TMCL) is still at the requirements stage, we used a schema language called OSL[21] and created rules such as the following:
<topic id="technology" match="strict">
<instanceOf>
<subjectIndicatorRef href="http://psi.xml.org/stdsreg/#technology"/>
</instanceOf>
<!-- BASE NAMES -->
<!-- omitted for brevity -->
<!-- OCCURRENCES -->
<!-- ditto -->
<!-- ROLES -->
<!-- must play role of "technology" in "responsibility" association -->
<playing min="1" max="1">
<instanceOf>
<subjectIndicatorRef
href="http://psi.xml.org/stdsreg/#technology"/>
</instanceOf>
<in>
<instanceOf>
<subjectIndicatorRef
href="http://psi.xml.org/stdsreg/#responsibility"/>
</instanceOf>
</in>
</playing>
<!-- more role player constraints -->
</topic>
Using such a schema, the seed topic map could be validated using the Omnigator, revealing whatever inconsistencies (errors or lacunae) might exist and enabling us to correct them.
As the controlled vocabulary of the seed topic map grows, the number of interesting keywords in the uncontrolled vocabulary becomes smaller and smaller, since any term in the uncontrolled vocabulary that also exists in the controlled vocabulary is simply ignored. However, a number of useful keywords remain, especially those representing more general concepts, such as "linking", "security", "metadata" and "web services". To cater for such keywords, we have introduced the topic type 'concept'.
The problem we encountered, however, is that it is difficult to devise a suitable controlled vocabulary for such relatively vague concepts. This is partly because they go under many different names, and partly because there are very many closely related concepts that may not be very interesting in themselves (because they would only be mentioned directly in one or two papers), but are interesting when taken together. To address this issue, we have introduced the notion of "concept clusters" – groups of terms that are so close in meaning, or that all belong to the same, very narrow domain, that it makes sense to regard them as a single topic for the purpose of navigation.
As an example, we take the domain of graph theory, which has been covered in a number of papers, but without necessarily refering to the term "graph theory" directly. Instead those papers might provide keywords such as "hypergraph", "subgraph isomorphism", or "graph, node, and edge". We create a single concept and give it what we consider to be the most appropriate name, in this case "graph theory", in the unconstrained scope. All other closely related terms are then specified as additional base names in the scopes "cluster-term" and "keyword", respectively. Cluster terms are terms which are candidates to become concepts in their own right, should this concept cluster end up with too many associated papers. Terms in the scope "keyword" are merely present in order to enable them to be removed during processing and reduce "noise" when we manually examine the remaining set of keywords after processing. The topic "graph theory" is shown below, in LTM syntax for brevity.[22]
[graph_theory : concept = "graph theory"
= "graphs" /cluster-term
= "hyperedge" /cluster-term
= "hypergraph" /cluster-term
= "hypermap" /cluster-term
= "hypernode" /cluster-term
= "subgraph" /cluster-term
= "topological graph theory" /keyword
= "graph drawing" /keyword
= "graph partitioning" /keyword
= "graph theory history" /keyword
= "graph clustering" /keyword
= "graph-oriented languages" /keyword
= "labeled graph" /keyword
= "graph, node, and edge" /keyword
= "dependency hypergraph" /keyword
= "element of a hypergraph" /keyword
= "subgraph isomorphism" /keyword
= "induced subgraph" /keyword
]
This topic, of type "concept", has one base name in the unconstrained scope, six in the scope "cluster-term", and 11 in the scope "keyword".
Our initial experiments suggest that this technique will further improve scanning and reduce the dependency on author-defined keywords, but more work is required before any final conclusions can be drawn.
Our use of the XMLvoc ontology and the Free XML Tools topic map already gives the first small indication of the ways in which topic maps permit the reuse and repeated leveraging of existing knowledge. We plan to take this further, for example by using the source files of the (now defunct) Whirlwind Guide ([Pepper 1992]) as further input to the scanner. (Although no longer maintained, the Whirlwind Guide is a rich source of products and vendors from the days of SGML, many of which are discussed in the papers of past GCA conferences.)
An even more interesting source is the Mondial database of geographical facts ([May 1999]) which we have converted to a topic map that will be put into the public domain in the near future. We intend to use this, together with the country topic map being created by the GeoLang TC of OASIS, as a knowledge base to be consulted during processing of the conference papers in order to ensure consistency in the naming of countries, cities and regions, and the many errors authors make in the use of the corresponding element types when creating their XML. It will also provide the ability to do interesting queries such as "How many talks were given by people from Asia at conferences in North America?" We hope to be able to demonstrate the results during the presentation of this paper.
Up to this point the XML Papers application has been developed using the Omnigator, which has again proven to be an ideal prototyping tool. The Omnigator can load topic maps in any syntax, including HyTM, XTM and LTM; this has been particularly useful since the seed topic map is being developed using LTM while the full topic map is generated as XTM. The Omnigator provides a generic interface centered around the notion of a "current topic", with each page displaying everything that is known about the topic in question in a user-friendly manner. It supports filtering, merging, schema-based validation, and querying (using tolog[23]), and has an interface that reveals inconsistencies and errors and is thus useful for debugging topic maps during development.
However, because the Omnigator is a generic tool, its interface is not suitable for end-user applications. Now that our ontology has stabilized and we have a clear idea of the kind of functionality and navigation that the portal should provide, the time has come to start developing a customized user interface with its own look and feel. The tool we are using for this purpose is the Ontopia Navigator Framework, a toolkit for building topic map-driven web delivery applications.
The Navigator Framework consists of a set of J2EE-compliant tag libraries that are used to create Java Server Page applications without the need for Java programming. The tags provide easy access to the contents of a topic map, via the API of a topic map engine, and the ability to manipulate them and generate various kinds of markup (HTML, XML, WML, etc.). The following code excerpt illustrates how the tag libraries are used; it shows how the names of all papers "written by" a certain author are retrieved from the topic map and output as HTML unordered list:
<!-- assumes a default variable containing a 'person' topic -->
<!-- set a variable (written-by) to the association type 'written-by'
using a subject indicator -->
<logic:set name="written-by">
<tm:lookup indicator="http://psi.ontopia.net/xmlconf/#written-by"/>
</logic:set>
<!-- set a new variable (papers) to all topics that play roles in
"written by" associations with the default topic -->
<logic:set name="papers">
<tm:associated type="written-by"/>
</logic:set>
<!-- if there are any such papers... -->
<logic:if name="papers">
<logic:then>
<!-- start a bullet list and iterate over the papers -->
<UL>
<logic:foreach>
<LI><output:name/></LI>
</logic:foreach>
</UL>
</logic:then>
</logic:if>
This example illustrates the use of tags from the logic library (set, if, then, foreach), the tm library (lookup, associated) and the output library (name). Altogether there are six such libraries containing approximately 60 tags. Most of these belong to the tm (or "topicmap") library which provides access to all aspects of the topic map data structure. The following is a complete list of tm tags: associated, associations, associationTypeLoop, classes, classesOf, filter, fulltext, indicators, instances, lookup, name, names, occurrences, reified, reifier, roles, scope, sourceLocators, subclasses, superclasses, themes, tolog, topicmapReferences, topics, variants.
The Navigator Framework can be thought of as "XSLT for topic maps": A tag-based transformation language optimized for use with topic maps. Using it, one of the authors (who could not write a line of Java code to save his life) was able to build the prototype application which will be demonstrated when this paper is presented.
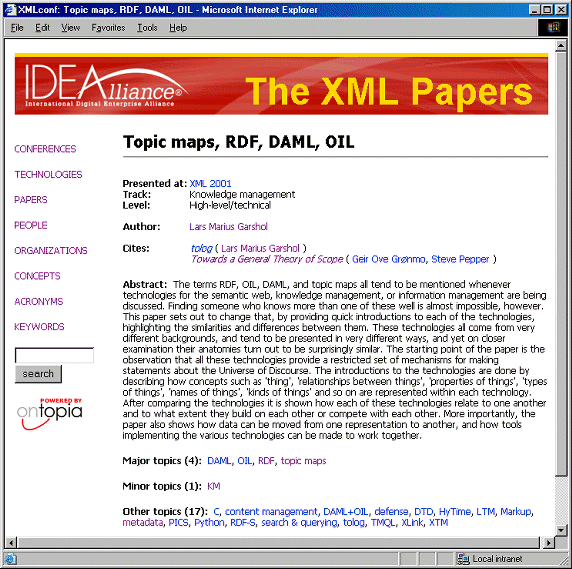
This application is in reality a topic map-driven web portal for XML information in the form of conference papers. Thanks to the underlying topic map it has many interesting features:
Consistency: The interface is far most consistent that would otherwise have been possible. Consistency also means user-friendliness.
Maintainability: The portal is very easier to maintain. For example, new conference papers can be added in seconds.
Navigability: The pages are remarkably easy to navigate, despite (and because of) the phenomenal richness of the interconnections. The navigational possibilities cannot really be described in words: they have to be experienced. We hope to make the prototype available online in the near future.
Queryability: Structured queries can be run against the data using tolog. At the moment these are only available internally to the application, or via custom buttons, but we are looking at user interfaces that might allow users to specify their own queries. Some examples of queries that are possible today are: ("Find me...")
| Content Management | application domain | name | 100% |
| Content Management and XML | paper | name | 81% |
| Content Management System (CMS) | tool category | name | 81% |
| Content management tools | tool category | name | 81% |
| Content Management Framework (CMF) | acronym | name | 81% |
| The Role of Names in Content Management | paper | name | 70% |
| Roadmap to Content Management with XML | paper | name | 70% |
| XML Content Management: Challenges and Solutions | paper | name | 63% |
| SGML Databases & Content Management for the Web | paper | name | 63% |
| XML & Content Management Special Interest Day | paper | name | 58% |
| Are Content Management Vendors Really on the XML Bandwagon? | paper | name | 58% |
| Developing a Business Case for XML-Based Content Management Systems | paper | name | 50% |
| Implementing an XML Content Management System for Drug Information | paper | name | 50% |
| The Ten Commandments of Content Management in a Database - Vest Pocket Edition | paper | name | 50% |
| Structure, Structure Everywhere! | paper | occurrence | 44% |
| Volker John | person | occurrence | 38% |
| Ray Luoma | person | occurrence | 38% |
| Using XML to Enable Low-Cost Deployment of Content at LockheedMartin Aeronautics | paper | occurrence | 32% |
Much work still remains to be done, but as can be seen the initial results of the project bode well. The GCA and IDEAlliance conference proceedings really are a gold mine, and the knowledge they contain is about to be made available in a portal that will provide convincing – and lasting – proof of the value of topic maps.
This paper has described some of the basic steps in applying topic maps in a real world application, a topic map-driven web portal of conference papers. It has covered the tasks of collecting and examining the data, defining the ontology and populating the topic map. It has discussed tools for automatically creating topic maps, with particular emphasis on how the synergies between topic maps and RDF can be exploited in the process of autogenerating topic maps from structured and semi-structured source data. It has also provided an introduction to the concept of published subjects, described how they are being applied in this application, and detailed the benefits that they are expected to bring in both this and other applications.
First and foremost we would like to thank IDEAlliance for allowing us to work on this project, in particular Jane Harnad, Tanya Bosse and Marion Elledge. Marion, along with Pam Gennusa and Tommie Usdin helped us with the early history of the GCA's conferences.
We wouldn't have got very far without source materials, so we would like to say an emphatic "So Long, and Thanks for All the Data!" to:
Dave Kunkel of IDEAlliance, who did his best to scrounge together whatever the information owner still had lying around. Pam Gennusa, the GCA's longest standing conference chair and probably the one with the best-kept archives. Michel Biezunski, who had taken care of significant amounts of data from his earlier work. Michel also deserves credit for the original idea of topic mapping GCA conferences – and for carrying the flag when everyone else had given up on the idea of topic maps.
Charles Goldfarb made sure that we didn't promulgate too many myths about SMDL and HyTime. Thanks, Charles. ZapThink supplied us with a basic set of markup languages (albeit unknowingly), and Erik Wilde came forward with his glossary and even went to the trouble of exporting it as a topic map for us. Thanks to both.
| 1 |
GML (Generalized Markup Language) was developed in the 1970's by three researchers at IBM: Charles Goldfarb, Ed Mosher, and Ray Lorie. Goldfarb went on to lead the standardization work which resulted in Standard Generalized Markup Language (ISO 8879) in 1986. He is justly regarded as the inventor of SGML and XML. |
|---|---|
| 2 |
A more accurate history of the development of SMDL and HyTime is to be found in [SIGhyper 1994]. Sadly, at the time of writing, SMDL is still on ice, awaiting a benefactor to sponsor the tiny amount of work that remains to be done. |
| 3 |
The fact that one of the early GCA conference papers on HyTime, by Michel Biezunski, was entitled "HyTime: Comparison between the space-time model and the space-time model used in physics" may have contributed to this. The abstract of that paper, presented at International Markup '92 reads as follows: "The space-time model in HyTime, which is based on music notation, proves useful for establishing a difference between 'real time' and "virtual time". Mr. Biezunski compares the HyTime model with the Special Relativity Space-Time Model used in physics in order to develop some uncovered aspects of the HyTime model in a different context." The name Michel Biezunski will crop up again in this paper. |
| 4 |
The requirement to be able to merge back-of-book indexes was based on a real use case encountered during work in the Davenport Group, which later went on to develop the DocBook DTD (see [Pepper 2000]). Early drafts of Topic Navigation Maps go back to 1994 and earlier. |
| 5 |
The name was changed during the standardization process when it was recognized that the new technology could be used for much more than "just" navigation. The proposal for the ISO work item read as follows: Scope: This standard provides a mechanism, based on techniques defined in ISO/IEC 10744:1992, for identifying information objects that share a common topic. It can also be used to define the relationships between sets of related topics. It can be used to define:
Purpose and justification: At present there are no standardized mechanisms for identifying multiple points within an electronic document that cover the same subject. ISO/IEC 10744:1992 (HyTime) provides a mechanism for identifying the relationships between multiple points in one or more documents without having to store the link information within the referenced documents. This new standard will allow HyTime independent links to be assigned semantics that identify the topic(s) interconnected through a particular multi-anchor link. These topic map semantic relationships can also be used directly within structured documents represented using the Standard Generalized Markup Language (SGML) defined in ISO 8879:1986 to identify relationships between the logical elements that make up an SGML document." [WG8 1996] |
| 6 |
That vision is described in [Berners-Lee 2001]. The existing RDF specification itself is in two parts ([Lassila 1999] and [Brickley 2002]), the second of which is still at draft stage. A new set of specifications, with a different syntax, is currently being developed by the W3C. |
| 7 |
The superficial similarities led Michael Sperberg-McQueen (in his closing keynote at Extreme Markup 2000, another GCA conference) to wonder whether both were really needed and to suggest that the developers of RDF and topic maps should be locked in the same room and not let out until they had agreed on a single model! |
| 8 |
For a succint discussion of some of the major differences between topic maps and RDF, see [Pepper 2002b]. For an in-depth examination of the relationship between the two see [Garshol 2001b] and [Garshol 2002], which also lists other work done on unifying the two models. |
| 9 |
Those of us that came to topic maps at this time still know more about Gentile Bellini and his works than the average man in the street! Those that came to topic maps later tend to know more about Italian opera than Italian painting... |
| 10 |
At the time of writing (October 2002), the index of indexes is still available online at http://www.infoloom.com/IHC96/ihc96idx.htm#indexes. |
| 11 |
For us, "legacy data" is any existing information that has not (yet) been topic mapped. |
| 12 |
Those tools were the components of the Ontopia Knowledge Suite (OKS) ([Ontopia 2002a]), consisting principally of a full-fledged Topic Map Engine in Java, a framework for building J2EE-compliant web delivery applications based on topic maps, a framework for building topic map editing environments, and an autogeneration toolkit, MapMaker. |
| 13 |
We are indebted to a number of people who have bent over backwards to search their own archives and those of the GCA to find at least some of the legacy data. They are named in the acknowledgements section. |
| 14 |
For an introduction to the basic concepts of topic maps, see [Pepper 2000]. |
| 15 |
Readers with weak sensibilities are warned that the news group chosen was rec.arts.erotica, mostly because it contained some interesting metadata fields not present in most news groups ... but in part also because we wanted to test how well our approach worked with really dirty data. |
| 16 |
[Garshol 2001b] actually lists six constructs, but the sixth, "instance of" is more correctly regarded as a syntactically privileged association. |
| 17 |
To find the answer, a simple tolog query ([Ontopia 2002e]) was performed on the topic map: select $A, count($B) from producing the following result:
|
| 18 |
For details of current activities in the ISO topic map committee, see the links available at http://www.isotopicmaps.org/sam/ |
| 19 |
The work of these committees is described at http://www.oasis-open.org/committees/tm-pubsubj/, http://www.oasis-open.org/committees/geolang/ and http://www.oasis-open.org/committees/xmlvoc/. |
| 20 |
To illustrate the homonym problem (same name, multiple subjects):
If I were to tell my colleagues that I am going to have a meeting with
OASIS in Baltimore, they would understand exactly what I mean, but not
be particularly impressed. If I were to say the same to my daughters,
they would be very impressed and ask me to make sure I got their
autographs! To clear up the misunderstanding I would have to make clear
that in the context of my work and my trip to the XML 2002
conference, the name "OASIS" refers to a different subject than the one
they assumed. |
| 21 |
The Ontopia Schema Language (OSL) is defined in [Ontopia 2002b] and [Ontopia 2002c]. |
| 22 |
The Linear Topic Map Notation (LTM) is a very compact topic map syntax that is supported by the Ontopia Topic Map Engine and the Open Source engine TM4J. It is defined in [Ontopia 2002d]. |
| 23 |
tolog is a topic map query language developed and implemented by Ontopia to provide input to the TMQL standardization effort. It is supported by both Ontopia's products and the Open Source engine TM4J. For a description, see [Garshol 2001a] and [Ontopia 2002e]. |