| By: | Lars Marius Garshol, Development manager |
|---|---|
| Affiliation: | Ontopia |
| Email: | larsga@ontopia.net |
| Web: | http://www.ontopia.net/ |
|
This paper describes a query language for topic maps called tolog. This query language is inspired by Prolog and, as described in this paper, supports everything described in the requirements for the ISO topic map query language TMQL. It has a clear and simple syntax, and its basic features are easy to implement.
This paper describes the language as implemented, extensions to make it serve as a full TMQL, explores possible uses of it, and discusses implementation considerations.
This paper describes an earlier version of the tolog query language. For the latest version, please see the tolog tutorial.
Lars Marius Garshol is currently Development Manager at Ontopia, a topic map software vendor. He has an MSc in Computer Science from the University of Oslo, and has been active in the XML community for a number of years. He is perhaps best-known for his Free XML Tools site, but has also written a fully validating XML parser in Python, translated SAX to Python and participated in many other XML-related open source projects. He has been a speaker at international XML-related conferences for several years.
Lars Marius has also been responsible for adding Unicode support to the Opera web browser. At the moment, he is completing his book on 'Developing XML Applications', to be published by Prentice-Hall in its Charles Goldfarb series later this year.
The first step on the way to making topic maps a viable standard for information representation and interchange has now been taken: a reasonably formal and complete specification has been published in the form of XTM 1.0 [xtm-1.0]. Among the logical next steps for the topic map community are to define a query language based on the XTM 1.0 specification, in order to make topic map application development both easier and also less dependent on products from specific software vendors.
The work on creating a standardized topic map query language, to be called , has already begun, and currently both a requirements specification [tmql-reqs-0.6] and an official proposal [ISO-N186] have been published. These documents have been written as part of an official ISO work item, and it is expected that TMQL, when finished, will be adopted as an official ISO standard.
In addition to this, work is underway on a processing model for XTM, which will serve as a formal basis for TMQL as well as specifying in more detail the behaviour expected from XTM processors.
This paper presents a query language for topic maps called which differs greatly from the current official TMQL proposal. The purpose of the paper is to explore an approach radically different to what others have already proposed, in order to see what virtue there may be this approach. It is also hoped that the material in this paper can inform the work on TMQL, regardless of what approach is taken in the final TMQL standard. (See [ISO-N186], [Ksiezyk00] and [Schmidt01] for related work.)
The discussions in this paper were informed by experience with an actual implementation of tolog, written in Jython, that is, Python in Java, as an application of the Ontopia Topic Map Engine, which is written in Java. The implementation has both a text-based interface, which is used to show query results in this paper, and a web-based interface, which will be used in demonstrations in the presentation.
I would like to thank my colleagues Steve Pepper and Geir Ove Grønmo for providing useful input in the writing of this paper.
A topic map is an abstract structure that contains information of interest to a community of users, just like a database. And just as with databases the users may be interested in not just walking around that structure to find information, but also in having the computer do the walking for them, and present the results of its walking. This operation, presenting information from an information structure in summarized and filtered form, is often called querying.
To query, according to my dictionary, means to put a question, but most query languages to date have been pressed into the service of other goals besides mere querying. For example, the SQL query language for databases is also used to define the database schema, to update and modify the database and also to implement business rules not expressible by means of the schema. These are all operations that may as well be applied to a topic map repository as to a database.
In the case of TMQL the tasks the language should be able to perform have been set forth in [tmql-reqs-0.6], and these are:
querying, as defined above, returning as results topics and topic maps,
adding information to the topic map, at all levels of granularity from sets of topics to individual properties of topic characteristics, and
deleting information from the topic map, at the same level of granularity as adding,
Modifying the topic map is not explicitly mentioned as a requirement, but one assumes that it will be made possible by a combination of addition and removal.
Initially, tolog was only intended to support querying, but as understanding of the language and its potential grew it was realized that tolog could in fact become a full TMQL if properly expanded. tolog also operates on a higher level of abstraction than the proposed TMQL and may perform operations that would be exceedingly difficult in TMQL. We will examine the relationship between TMQL and tolog in more detail later, once the full tolog language has been introduced.
Queries formulated by a human being, whether in a formal syntax or via some more helpful interface, are likely to attempt to locate either topics or associations, or possibly both. The characteristics by which humans are most likely to want to find topics are:
their types,
their names, and
their associations.
The main capability of tolog is to specify association templates that can be filled in by the tolog query engine. Being able to search for topics by their associations at the same time provides the possibility to search for the associations themselves. Treating class-instance relationships as associations, which the XTM specification in any case does in annexes B and F, means that the ability to search for topics by their types is also provided. Being able to search for topics by their names is not part of the base language, but extensions to provide this are considered below.
In some cases, primarily as part of application development, it may also be interesting to look up topics by their addressable subject, subject indicators, occurrences and perhaps even URIs. This is not supported by the basic tolog language at all, but is addressed by the extensions proposed in this paper.
A related question is: what should topic map queries be matched against? One option is to use the XML interchange form of the topic map and match queries against this. This, however, is not very useful, for the following reasons:
The root XML document of the topic map does not necessarily contain the entire topic map, since there may well be mergeMap elements that refer to other topic map documents. Similarly, there may be topicRef elements referring to other topic map documents that should be read in. Generic XML tools would generally not be aware of this, and so not query the entire topic map.
In XML form the topic map may not be what the XTM specification calls 'consistent', that is, there may be several topic elements that represent the same subject, and there may be duplicate base names, occurrences and associations. Searching on the topic map in this inconsistent form may mean that queries fail that should not.
Most topic maps used in real applications are not going to exist as XML documents at all, except possibly for interchange purposes, but will be maintained in some form of database. In order to query these topic maps as XML documents they must be mapped to their XML representation, which is unlikely to be either efficient or convenient at all.
In short, some form of abstract structure which can be used to represent the topic map after processing is needed. In implementations of query languages this is likely to be database contents in various forms, specially-built indexes and object structures of various kinds. In order to ensure interoperability the requirements placed on these structures must be specified, as well as how queries are interpreted in terms of these structures, and this is listed as one of the requirements for TMQL [tmql-reqs-0.6]. The structure could be specified using some object-oriented language (that is, it could be an object model), it could be specified mathematically, or it could be specified using some specialized schema language like HyTime property sets or ISO 10303 EXPRESS.
It is expected that the topic map community will produce a processing model that addresses this need before very long. For this paper we will only use an informal abstract model.
tolog is very closely based on , a near-declarative logic programming language based on first-order predicate logic [ISO13211]. Central to both languages are the concept of a fact database containing statements about the universe of discourse, that is, the subject area of the database. If the subject area were Italian Opera, one would expect to find statements like "Tosca (an opera) was composed by Puccini", "Puccini was born in Lucca" and so on in the database.
In a topic map, these statements would be expressed as associations, like "Tosca plays the role of opera in a composed-by association where Puccini plays the role of composer", "Puccini plays the role of person in a born-in association where Lucca plays the role of place", etc. (These associations were taken from Steve Pepper's Italian Opera topic map [italian-opera], which will be used as the example topic map throughout this paper.)
In tolog and Prolog, such statements would be expressed as
composed-by(tosca, puccini). and born-in(lucca,
puccini).. The tolog factbase does not duplicate the
information in the topic map, but is populated by mapping the
associations in a topic map to such tolog statements.
In Prolog, as in tolog, the order of the individual indentifiers in a
statement are significant, which means that all born-in statements
must have the city first and the person second. In topic maps,
however, association roles within an association have no particular
order and so something is needed to define the order of the
identifiers in the set of facts that an association is mapped to. In
tolog this is done via a rules file. Putting the statement
composed-by(opera, composer). into the rules file will
make all composed-by associations into statements with the opera first
and the composer second. (An extension to make this unnecessary is
discussed below.)
The identifiers used in the rules file are the IDs of the topics that represent the association type and assocation role types. How IDs are assigned to topics is left to the tolog implementation to decide, as long as the IDs are valid XML IDs.
Queries look very much like facts in that they are syntactically
composed of clauses. Giving the query composed-by($A,
$B). to the tolog query engine is asking it to find all values
for the variables A and B that match the information in the fact
base. The result will be a list of different assignments to A and B;
in fact, the list will hold all composed-by associations in the topic
map.
This, of course, is rarely interesting, and so we can reformulate the
query. composed-by($A, puccini). asks for all values of A
that make the statement true, or, to put it another way, for all
operas that have a composed-by association with Puccini. The result will
be all operas composed by Puccini. In the text-based tolog interface,
this is shown as below.
[{'A': 'gianni-schicchi'},
{'A': 'madama-butterfly'},
{'A': 'tosca'},
{'A': 'edgar'},
{'A': 'la-boheme'},
{'A': 'il-trittico'},
{'A': 'le-villi'},
{'A': 'la-rondine'},
{'A': 'suor-angelica'},
{'A': 'la-fanciulla-del-west'},
{'A': 'il-tabarro'},
{'A': 'manon-lescaut'},
{'A': 'turandot'}]
In fact, there is no need for there to be any variables at all in a
query. Asking the query engine composed-by(tosca,
puccini). will return a single empty match, which means that
this specific fact (or association) is found in the topic map. The
text-based interface shows this as [{}]; that is, a
single match which caused no variable assignments. If there are no
matches the query will return an empty list of matches, which is
subtly different from a list containing a single empty match.
More advanced queries are also possible by combining several clauses
with commas; the commas can be read as 'and' operators. The query
composed-by($A, puccini), written-by($A, $B). asks for
all As and Bs where A is composed-by Puccini and has a libretto
written by B. In other words, we ask for all librettists that wrote
the libretto for an opera written by Puccini as well as the operas
they collaborated on.
To understand this query it is necessary to understand how querying works. First, the engine finds all As that make the first clause true; that is, it finds all operas written by Puccini. Then, it moves on to the second clause and for each A creates a match for every librettist who worked on A. If no librettist worked on A, the A is simply forgotten. The end result of the query is the list of matches created by the second clause. In the text-based interface that list looks as shown below.
[{'A': 'gianni-schicchi', 'B': 'forzano'},
{'A': 'madama-butterfly', 'B': 'illica'},
{'A': 'madama-butterfly', 'B': 'giacosa'},
{'A': 'tosca', 'B': 'illica'},
{'A': 'tosca', 'B': 'giacosa'},
{'A': 'edgar', 'B': 'fontana'},
{'A': 'la-boheme', 'B': 'illica'},
{'A': 'la-boheme', 'B': 'giacosa'},
{'A': 'le-villi', 'B': 'fontana'},
{'A': 'la-rondine', 'B': 'adami'},
{'A': 'suor-angelica', 'B': 'forzano'},
{'A': 'la-fanciulla-del-west', 'B': 'zangarini'},
{'A': 'la-fanciulla-del-west', 'B': 'civinini'},
{'A': 'il-tabarro', 'B': 'adami'},
{'A': 'manon-lescaut', 'B': 'praga'},
{'A': 'manon-lescaut', 'B': 'illica'},
{'A': 'manon-lescaut', 'B': 'giacosa'},
{'A': 'manon-lescaut', 'B': 'ricordi'},
{'A': 'manon-lescaut', 'B': 'oliva'},
{'A': 'turandot', 'B': 'simoni'},
{'A': 'turandot', 'B': 'adami'}]
As before, multi-clause queries can consist of all variables, such as
this query: died-in($A, $B), born-in($A, $B).. This query
will first find all died-in associations and represent them as a list
of matches, or assignments to A and B. The evaluation would then move
on to the second clause and evaluate that clause with the values for A
and B inserted. This second evaluation would create a set of matches,
possibly empty, from the second clause for each match from the first
clause. The result of the query is this new list of matches (the list
of matches from the first clause is just discarded), which will
contain only people who died in the same place as they were
born. Using the Opera topic map we get this result.
[{'A': 'illica', 'B': 'piacenza'},
{'A': 'giacosa', 'B': 'colleretto-parella'}]
There are many died-in associations in the topic map, but only two of them create any matches when matched against the second clause.
The other main feature of the language is the ability to create rules based on the facts in the topic map. Such rules can in turn be queried as if they were facts, and so the rules in a way create virtual associations in the topic map. One example of a rule might be:
used-work-by($A, $B) :- composed-by($OPERA, $A),
based-on($OPERA, $WORK),
written-by($WORK, $B).
which says that A has used work by B if A has written an opera that is
based on a work written by B. With this rule in the rules file we can
run the query used-work-by(puccini, $A)., which gives us
the result below.
[{'A': 'dante'},
{'A': 'belasco'},
{'A': 'sardou'},
{'A': 'musset'},
{'A': 'murger'},
{'A': 'gold'},
{'A': 'prevost'},
{'A': 'gozzi'}]
Of course, new rules can be formulated that build on existing rules in various ways.
There is no 'or' operator for rules, but if there are two separate rules with the same name queries will succeed if they match one of the two rules. This means that writing two rules works just as if there were only one rule that used an 'or' operator.
The tolog language also contains two predefined rules: has-type and
/=. The first makes it possible to verify whether a topic is an
instance of a given class or not, for example as in
has-type(puccini, composer).. The query has-type($A,
composer). will return all topics of the type composer.
The /= rule, or operator, is used to compare two topics to see if they
are the same. The query born-in($A, $B), born-in($C, $B).
will return all As and Cs that are born in the same B. The trouble is
that this will also return lots of cases where A and C are the same
topic. Reformulating the query to born-in($A, $B), born-in($C, $B),
$A /= $C. solves this problem.
The base tolog language as presented up to this point is simple to understand, and, experience has shown, relatively simple to implement. The original implementation, minus has-type and /=, was written in a single night, and has essentially been unchanged since.
The base language, although simple, can perform quite sophisticated queries, and provides substantial benefits for topic map application developers and power users in return for very limited effort. As such, the language has a good cost/benefit ratio.
As it stands, however, the language has a number of weaknesses:
it can only query on associations, and it can only return topics as query results,
it is heavily based on unique IDs for topics, which in most cases are likely to be automatically assigned (since XML IDs cannot be guaranteed to be unique when topic maps are loaded from several XML documents) and thus lead to hard-to-read tolog queries,
in order to query a topic map a rule file must be written first, which may be awkward, and
the language can only query the topic map and not modify it in any way.
It is difficult to see any good solution to the problem of topic IDs, and no other topic map query proposals have offered any better solutions, so this is arguably not a weakness of tolog. The other three weaknesses will be addressed in the following.
Before moving on to extensions and modifications to the base language we will look at possible ways of using the query language, in order to better understand how to make use of it and also what extensions to the language might prove useful. The uses described in this section may also apply to TMQL in whatever form that may have when it is completed.
Developing topic map application software is currently done by writing code against the API of some topic map engine that traverses the topic map in question to perform some useful task. In applications specific to a particular ontology (or topic map schema) it seems likely that applications will want to operate on information extracted from the topic map using various kinds of criteria. Some of these criteria might be fairly complex, and thus far better expressed using a query language.
To make this discussion more concrete I will use the development of a web site based on the Italian Opera topic map as an example here. This web site might have a top page describing the site and offering the user a choice of navigating the topic map by either composer, opera or country. When the user selects one of these a list of topics of that type are presented, with links to the home page of that topic.
For each topic type there will be a script that produces the pages belonging to topics of that type. For composers, this page might start off with the composer's name, a table of facts (culled from occurrences and associations), a list of operas composed by the composer, and a list of librettists the composer collaborated with. One could think of more information to include, but to keep the examples simple we stop here. An example of such a page is shown below.
A composer page
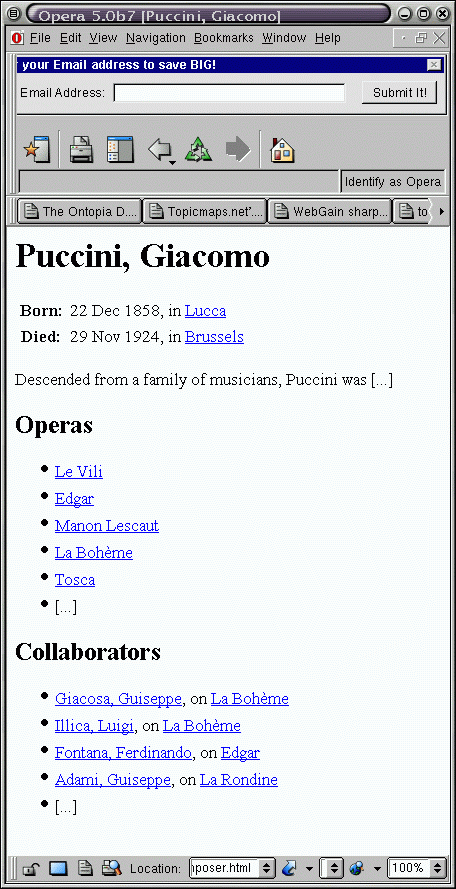
If the script producing this page were written as a Java Server Page (JSP) using the open source Java topic map engine the source code for producing the lists of operas and composers might be as shown below. (HTML output is given directly, while Java source code is contained in <% %>).
<%
Topic composer = topicmap.getTopicById(id);
Topic composedBy = topicmap.getTopicById("composed-by");
Topic operaType = topicmap.getTopicById("opera");
Topic writtenBy = topicmap.getTopicById("written-by");
Topic librettistType = topicmap.getTopicById("librettist");
%>
<h2>Operas</h2>
<ul>
<%
Iterator it = composer.getRolesPlayed().iterator();
while (it.hasNext()) {
Member member = (Member) it.next();
if (!member.getParent().ofType(composedBy))
continue;
Association assoc = member.getParent();
Member opera = assoc.getMemberOfRole(operaType);
// ...output <li><a href="opera-url">opera-name</a></li>...
}
%>
</ul>
<h2>Collaborators</h2>
<ul>
<%
it = composer.getRolesPlayed().iterator();
while (it.hasNext()) {
Member member = (Member) it.next();
if (!member.getParent().ofType(composedBy))
continue;
Association composedByAssoc = member.getParent();
Member operaMember = composedByAssoc.getMemberOfRole(operaType);
Topic opera = (Topic) operaMember.getPlayers().iterator().next();
Iterator it2 = opera.getRolesPlayed().iterator();
while (it2.hasNext()) {
Member operaMember2 = (Member) it2.next();
if (!operaMember2.getParent().ofType(writtenBy))
continue;
Association writtenByAssoc = operaMember2.getParent();
Member librettistMember = writtenByAssoc.getMemberOfRole(
Topic librettist = (Topic) librettistMember.getPlayers().iterator().next();
// ...output <li><a ...>librettist</a>, <a ...>opera</a></li>...
}
}
%>
</ul>
</html>
If we were to use tolog for this, however, the source code would look rather different. The tolog implementation might be represented by a class TologDatabase with a method runquery(String query) which returns an object of the class TologQueryResult. Using this, the source code might be written as shown below.
<%
Topic composer = topicmap.getTopicById(id);
%>
<h2>Operas</h2>
<ul>
<%
TologQueryResult cursor = database.runquery("composed-by($A, " + id + ").");
while (cursor.nextMatch()) {
Topic opera = cursor.get("A");
// ...output <li><a href="opera-url">opera-name</a></li>...
}
%>
</ul>
<h2>Collaborators</h2>
<ul>
<%
cursor = database.runquery("composed-by($C, " + id + "), written-by($C, $B).");
while (cursor.nextMatch()) {
Topic opera = cursor.get("C");
Topic librettist = cursor.get("B");
// ...output <li><a ...>librettist</a>, <a ...>opera</a></li>...
}
%>
</ul>
</html>
Clearly, having tolog available greatly simplifies traversing associations, which is often one of the most awkward tasks for topic map developers, given the complex structure of associations.
In large topic maps it may often be more convenient for users to search for what they want than to find it by navigating around the topic map. Implementing queries directly on top of an API that exposes nothing but the structure of the topic map itself is rather awkward and painful, however, and so a query language comes in handy.
The interface used to specify the query can be designed in many ways. Some examples are:
a generic interface where the user can select the type of the topic, and also some association types and in what way the topic is to be related to other topics.
an interface specific to a particular topic type, which has the kinds of associations such topics are known to participate in already preselected to make the job easier for the user.
a natural language interface which uses the topic map to interpret queries and rewrites them to queries in the query language. This has been tried and it turned out to be astonishingly simple to get something that worked provided the user adhered to certain conventions, which frequent users might well do.
All these variations are possible, and can be relatively easy to implement when a query language implementation is available.
One thing that is likely to often be wanted for this kind of functionality, but which basic tolog does not provide, is searching for topics by their names. We will look into whether this can be done or not in the next section.
Implementing a query language that can efficiently execute queries on information structures that may hold millions of elements is by no means easy, but it is also an absolute requirement for a real query language. This section examines some of the possible implementation strategies and optimizations that can be applied to basic tolog.
As is also the case with SQL, queries with the exact same meaning can often be formulated in different ways, and the different variants of the query may have wildly different performance characteristics. If query engines could rewrite the queries to a more optimal form before executing them, much time and effort that would otherwise be devoted to learning and optimization can be saved.
composed-by($OPERA, $A), based-on($OPERA, $WORK), written-by($WORK, shakespeare).
As an example, consider the above query. The straightforward query implementation will first collect all composed-by associations, then for each of those create a new match for each based-on association the opera has. There will therefore be a large number of matches to apply to the second clause, and the result will be another large list of matches to be applied to the third clause. It is the third clause, of course, which reduces the number of matches to a manageable number, since it only accepts those which involve a work written by Shakespeare.
If in the second clause $OPERA had been replaced by for example $B, the number of matches after the second clause would have been the number of composed-by associations times the number of based-on associations. If, however, the third clause were moved first, things would look rather different, since evaluation will start out with a small number of matches.
written-by($WORK, shakespeare), based-on($OPERA, $WORK), composed-by($OPERA, $A).
The query above is identical in meaning to the first, but is much faster to execute, since it generates a small number of matches to begin with, and none of the following matches increase the number of matches very much. Note that if the last clause had been in the middle that clause would have generated lots of possible matches, since when it was evaluated neither OPERA nor A would have been bound yet. Below is a table that shows the running times for the different variants of the query in the prototype implementation.
| Query order | Time |
| (O, A), (W, s), (O, W) | 13 |
| (W, s), (O, A), (O, W) | 6.6 |
| (O, A), (O, W), (W, s) | 4.9 |
| (W, s), (O, W), (O, A) | 0.6 |
So, obviously the time to execute the query depends greatly on the number of matches generated by each clause, which again depends on the number of free, or unbound, variables in that clause. The sorting algorithm can be described as follows in executable pseudo-code:
def optimize_order(clauselist):
optlist = []
bound = {}
while clauselist:
lowest = 10000
best = None
for clause in clauselist:
count = count_free_vars(bound, clause)
if count < lowest:
lowest = count
best = clause
optlist.append(best)
clauselist.remove(best)
for arg in best.get_arguments():
if is_variable(arg):
bound[arg] = 1
return optlist
This, however, is not all that needs to be said of this matter. The order of the clauses is independent of the final result when only facts are used in the clauses, but when rules are used problems can arise. As an example, see the rule below.
descendant-of($A, $B) :- child-of($A, $B). descendant-of($A, $B) :- child-of($A, $C), descendant-of($C, $B).
This is a recursive rule that can be used to compute all descendants or ancestors of a given person, and also to test whether there is an ancestor/descendant-relationship between two people. It first checks whether the two are related by a parent/child-relationship. If not, it finds a child C of A and tries to see if that C may be an ancestor of B. The problem here is that if the two clauses in the last line are swapped queries that use the second rule can never fail, because they will recurse back on the rule itself and never reach the child-of clause that will break the recursion when the person has no known children.
The easiest solution to this problem is to traverse the graph of rules using other rules and turn off clause reordering for rules that are recursive, whether directly or indirectly.
What to do about the /= operator may not be immediately obvious. It is rather special in that it requires any variables used to have values assigned to them, and so cannot be placed anywhere in a query. The solution is to order the query without any /= clauses, and then insert the /= clauses after the clause the binds the last of the variables in the /= clause to be bound. This ensures that the /=, which is very fast to execute and can eliminate large numbers of matches, is executed as early as possible, without causing it to be executed before it has any values to work with.
When topic maps get really large, or when several clients may modify them simultaneously, it is infeasible to keep them in memory, and databases of some sort must be employed. Topic maps of such sizes cannot be queried by simple traversal, and so some more efficient means of querying needs to be employed. The obvious solution is to rewrite queries to queries in the query language of the database, and to do as little post-processing of the query results as possible.
If the topic map is stored in an RDBMS the tables used for associations and association roles might look as shown above.
CREATE TABLE TM_ASSOCIATION ( id INT NOT NULL PRIMARY KEY references TM_OBJECT (id), type_id INT NOT NULL references TM_TOPIC (id) ); CREATE TABLE TM_ASSOCIATION_ROLE ( id INT NOT NULL PRIMARY KEY references TM_OBJECT (id), assoc_id INT NOT NULL references TM_ASSOCIATION (id), type_id INT NOT NULL references TM_TOPIC (id), player_id INT NOT NULL references TM_TOPIC (id) );
Using this schema, the tolog query composed-by($A,
puccini). could be rewritten to the SQL statement below. (The
example uses strings as IDs for readability.)
select B.player_id
from TM_ASSOCIATION, TM_ASSOCIATION_ROLE A, TM_ASSOCIATION_ROLE B
where TM_ASSOCIATION.type_id = 'composed-by' and
TM_ASSOCIATION.id = A.assoc_id and A.type_id = 'composer' and
TM_ASSOCIATION.id = B.assoc_id and A.type_id = 'opera' and
A.player_id = 'puccini';
Most queries, however, will consist of more than one clause, and to
work efficiently the query engine needs to be able to chain together
several clauses into a single SQL query. This is not too difficult, as
it turns out, although the queries quickly become incomprehensibly
large for humans. The query died-in($A, $B), born-in($A, $B).
becomes as shown below in SQL.
select A1.player_id, A2.player_id
from TM_ASSOCIATION A, TM_ASSOCIATION B,
TM_ASSOCIATION_ROLE A1, TM_ASSOCIATION_ROLE A2,
TM_ASSOCIATION_ROLE B1, TM_ASSOCIATION_ROLE B2
where A.type_id = 'died-in' and B.type_id = 'born-in' and
A1.assoc_id = A.id and A1.type_id = 'person' and
A2.assoc_id = A.id and A2.type_id = 'place' and
B1.assoc_id = B.id and B1.type_id = 'person' and
B2.assoc_id = B.id and B2.type_id = 'place' and
A1.player_id = B1.player_id and
A2.player_id = B2.player_id
Queries consisting of more clauses can of course also be chained together. When it comes to queries where some of the clauses are rules rather than facts things get rather more complicated, and I have not yet been able to try out how to handle these cases. It is conceivable that in some cases it might be possible to generate nested queries, or that the tolog queries might be expanded by rewriting them to include the bodies of the rules inline. These avenues have not yet been fully explored, however, and so I will say no more of them here.
So far, only a very simple language has been presented compared to the full Prolog language, which in fact is a complete programming language providing many features beyond simple evaluation of queries. In this section of the paper we examine various possible extensions to the base language, with the intention of exploring how tolog can be made more convenient to use for developers and also how it can be made to support operations the base language cannot perform.
In order to support the language extension discussions it may be useful to examine the base language in a more formal way to understand how it works. Tolog queries consist of a list of clauses, where each clause contains a list of values, and values may be either variables or topics.
Query evaluation is done by sequentially matching each clause against the topic map that is being queries. In fact, matching is the fundamental operation of tolog. The result of matching a clause is a list of matches, which are sets of variable assignments. For each match, a separate step of variable resolution and subsequent matching is performed on the next clause. The result of processing that clause is the total list of all matches produced by the clause, while the matches produced by the previous clause are all discarded. When there are no more clauses the current list of matches is the query result. In the base language variables can only have values of one type: topics.
Matching a clause against a rule works the same way as matching it against a set of facts. To produce the list of matches the query specified by the list of clauses in the rule definition is performed, using a set of variable assignments specified by the context in which the rule was invoked.
Experience has shown that two types of transformations on the results
of a query are particularly often desired. The simplest is to only
include some of the variables in the query in the result. For example,
when executing composed-by($OPERA, $A), based-on($OPERA, $WORK),
written-by($WORK, shakespeare). we may not be interested in the
operas and works, and so may want only the values of A. This
transformation is simple to implement and can be very useful in
generic user query interfaces. For application developers this
transformation is of no interest at all, since unwanted values are
simply never looked up.
A more complex operation is that of sorting the list of matches, which can be specified by listing which variables to sort by and whether to use ascending or descending order. When saying that we want the query above sorted by A, B, ascending the matches can be sorted by the sort name of the topic assigned to A in each match. For matches where the same topic is assigned to A, the sort name of the topic assigned to B can be used to differentiate.
Sorting turns out to also not be too hard to implement, though it can be rather costly as traversing the name tree of a topic to find an appropriate sort name is a non-trivial operation and it may need to be performed once for every comparison during sorting. When implementing tolog on top of a database (about which more below) the operation may become very costly indeed.
Sorting is useful both in generic user interfaces and application development in general.
For all association types one wishes to access from tolog the rules file must contain a fact statement which maps the association type into a set of tolog facts. This means that one must write a configuration file for a topic map before being able to use it at all, which is somewhat awkward. The question is, can we avoid this somehow?
The problem solved by the fact statements is that in a clause like
composed-by($A, $B). it is nowhere said whether A is the
composer or the opera, and similarly with B. If the clause is joined
with another clause that uses some of the same variables it may be
possible to work out this information using inference on the existing
data in the topic map. This is, however, not a trivial task, and it
will not be possible with all queries in all topic maps.
maps.
What is possible is to put the information in the clause itself, as in
composed-by($A : opera, $B : composer).. This does away
with the mapping rules entirely, but means that both rules and queries
become longer. It also means that one no longer need remember the
order of the elements in a clause, but if the convention of writing
clauses so that the association type can be placed inline to form a
sentence this makes little difference. (I.e., opera composed-by
composer, rather than composer composed-by opera.)
used-work-by($A, $B) :- composed-by($OPERA, $A),
based-on($OPERA, $WORK),
written-by($WORK, $B).
Rules complicate this solution somewhat, since it is not immediately obvious how to define a substitute for order in rules. In the rule above, for example, how do we define what A and B are? The best solution seems to be to use association role types, just as in associations, thus assigning assocation role types to the topics that are in the result sets of rules. This might be done as below.
used-work-by($A : composer, $B : writer) :-
composed-by($OPERA : opera, $A : composer),
based-on($OPERA : result, $WORK : source),
written-by($WORK : work, $B : writer).
This solution does remove the need for the rules file if only simple facts are wanted, but at the cost of making all tolog statements longer and also more difficult to write, since the author needs to remember the correct role types used in all associations and rules. And if queries are to be able to make use of rules (and not just fact mappings) a rules file is needed in any case.
An interesting idea is whether it might be possible to somehow represent the tolog rules file using topic map constructs. For example, it should be possible to represent a clause in a query or rule as an association of a predefined type. This idea was first put forward in [Ksiezyk00]. Below is shown an example of what it might look like in tolog. (Note that the PSIs point nowhere, since they are used here for illustration and nowhere else.)
<association>
<instanceOf>
<subjectIndicatorRef xlink:href="http://psi.ontopia.net/tolog/clause"/>
</instanceOf>
<member>
<roleSpec>
<subjectIndicatorRef xlink:href="http://psi.ontopia.net/tolog/assoctype"/>
</roleSpec>
<topicRef xlink:href="#composed-by"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#composer"/>
</roleSpec>
<topicRef xlink:href="#puccini"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#opera"/>
</roleSpec>
<subjectIndicatorRef xlink:href="http://psi.ontopia.net/tolog/var-A"/>
</member>
</association>
This association would be recognized by the query engine as a tolog query clause through the topic used as the association type. The first member says that we are querying associations of the composed-by type. The second that we only want those where Puccini plays the role of composer, and the third associates the variable A with the topics playing the role of opera in the associations we find.
Of course, in this solution there is no need for the mapping rules, since the query and rule clauses both contain the association role types explicitly. What we still haven't solved, however, is how to represent rules. A rule consists of a head followed by a list of clauses, which we now represent as associations. To be able to represent the head we must have an association specying the variables visible from outside, and also the associations that make up the clauses of the rule.
In order for the rule association to be able to speak about the clause associations we would need to create topics that reify each of the associations that make up the clauses in the rule. The rule association would then knit together the reifying topics with the variable topics. The XML for this is omitted, as it would be rather painfully verbose, but it really does work.
The idea of representing topic map queries as topic maps has been popular in many quarters, since it has been perceived as both elegant and practical in the sense that it is believed to make it easier to reuse topic map software for working with queries. Any perceived elegance, however, is in my opinion bought at too dear a price in terms of the complexity of the query representation.
As for reusing topic map software to work with queries, for example in user interfaces, I believe that while it may be possible to reuse software to create user interfaces for topic map queries it will be equally simple without this representation. The parameters to queries are topic map constructs in any case and so provide opportunities for reuse regardless of how the queries are represented.
In addition to this, the syntax here proposed is just a syntax, and tools that wish to do so can express the queries as topic maps if they so wish, and convert to the syntax given here to have the queries executed.
There are three main ways in which tolog can be extended:
by adding new predefined rules like has-type,
by adding new datatypes, and operators and rules to work with these, and
by extending the syntax and adding entirely new concepts.
In order to add a predefined rule what needs to be specified is the
relationship between the parameters of the rule. That is, it needs to
be decided what values are bound to A and B when foo(bar,
$A) is evaluated, when foo($A, bar) is evaluated
and when foo($A, $B) is evaluated. In some cases, the
possible values for one of the parameters may be infinite, and in
these cases attempts to leave that parameter open must be considered
an error.
In the example of has-type(topic, type). the meaning of
each possible variation is clear:
has-type(foo, $A). will bind A to all the topics
that have been used to type foo,
has-type($A, foo). will bind A to all the topics
of type foo, and
has-type($A, $B). will return all (topic, type)
pairs in the topic map. The number of matches is likely to be very
high, but it will not be infinite, and so this is accepted.
In order to work with names the type system of tolog needs to be
extended with two types: strings and base names. Strings may appear in
the syntax, enclosed in '', and be returned by matches, while base
names may be returned as the result of matching. The rule
has-name(topic, basename, pattern). is used to do actual
searching by basenames. The patterns use Perl regular expression
syntax and semantics, since these can be used in most programming
languages.
With this rule, the following queries are possible:
has-name($A, $B, ".*Puccini.*")., which will bind
A and B to all (topic, basename) pairs where the base name contains
the string Puccini,
has-name(puccini, $B, $C)., which will bind B and
C to a (basename, string-value) pair for each base name the topic
puccini has, and
has-name($A, $B, $C)., which will create a match
for every base name in the topic map.
The utility of returning base names may not be immediately obvious, since nothing can be done with them in the base language once they are bound to a variable, but this will be shown below. More effort should probably be put into also handling variant names in a sensible way, but we leave that for now, wishing only to present the general idea.
Occurrences are of two kinds: external and internal, where the former are addressed by URIs and the latter represented as strings. Using a string parameter, rules that work the same way as has-name can be devised for occurrences:
has-occurrence(topic, occurrence, pattern)., for
querying external occurrences, and
has-occurrence-value(topic, occurrence,
pattern).
As with base names, it may not be clear why we wish to make the occurrences themselves available, but this will be explained in the following section.
Base name and occurrence values can also be made use of in querying if rules are added that work on these values. The has-type rule, for example, could be extended to accept not just topics, but also occurrences.
Querying by scope can be done by asking whether a particular topic
characteristic has a particular topic in its scope. Testing for more
complex scopes can then be done with more than one clause. The rule
has-scope(topic-characteristic, topic-in-scope). provides
this facility. With it, queries like these can be constructed:
has-name($A, $B, "Paris"), has-scope($B, texas). in
order to find Paris, Texas by its name, and
has-occurrence($A, $B, "http://www\.ontopia\.net.*"),
has-scope($B, norwegian). to find all topics which have an
occurrence on the Ontopia web site written in Norwegian.
With these extensions, the reach of tolog has suddenly been extended beyond associations and now covers most of the topic map model. To make it possible to query by subject address and subject indicators is simply a matter of adding more predefined rules, for example has-subject and has-subject-indicator.
Support for deleting objects from topic maps, and not just topics, could be provided through an additional rule delete, which never fails, and which cannot be used on free variables, but which marks all values passed to it for deletion and deletes them after the query evaluation has completed.
Using this rule one can issue the following requests:
has-type($A, homepage), delete($A)., removes all
occurrences of the type homepage,
has-scope($A, from-topic-map-X), delete($A).,
removes all characteristics that came from topic map X,
and
has-type($A, composer), born-in($A, $B), located-in($B,
$C), $C /= italy, delete($A)., removes all composers not born in
Italy.
Of course, deletion of topics and topic characteristics are problematic operations, in that it is not entirely clear what should happen with references to deleted topics and what should happen with a topic when all its characteristics are removed. Adding support for modifying the topic map also means that all the problems of concurrent modification raise their ugly heads, requiring some form of transaction support. These issues apply to all query languages equally, however, so I will say no more of them here.
Adding information to a topic map can be catered for by adding a keyword which, when used in front of a clause, implies that what is described in the clause should be added to the topic map. IDs which do not refer to any topics will cause the topic to be created.
The statement $ADD has-type(wagner, composer). will add
the topic wagner, and at the same time give it the type composer.
Following up with $ADD has-name(wagner, "Richard Wagner").
will give the topic a base name, while
$ADD born-in(wagner, leipzig). will add a new association.
Many topic maps are likely to make use of occurrences which hold simple data values like numbers and dates. If schema information were available for a topic map, so that the query engine could know the types of the values unambiguously, this might be turned to effective use in the query language.
has-occurrence-value could then operate with strings, numbers and dates, operators like binary comparators could be added, and one could find the first Italian opera with the following query:
has-type($A, opera), has-occurrence-value($A, $B, $C), has-type($B, premiere-date)
If this query were sorted by the values of C the first returned result would be the opera in the topic map that had its premiere first.
More radical extensions still could also be envisioned, such as adding the programming features of Prolog to turn tolog into a full programming language, able to interact with its environment. The benefits of turning tolog into a full programming language are that would make it possible to do application development in a language designed especially for topic maps. This would be likely to prove highly convenient for topic map developers, and would most likely make substantial differences to developer productivity, just as we have seen XSLT do for XML translation developers. To describe these possibilities here, however, would make this paper unacceptably long.
The tolog base language as proposed in section 2 seems to provide a high degree of convenience and utility at a low price in implementation effort. It may therefore be attractive for implementors and vendors, especially as a temporary solution before the official TMQL is completed.
As has been shown, simple tolog queries can be implemented efficiently on top of database-based topic map implementations. Whether more complex queries using several layers of rules can be made efficient in database implementations is as yet unclear.
As has also been shown, tolog can be extended to perform many of the same tasks as are required of a full TMQL, and so it may turn out to be a viable candidate for the final standardized TMQL. More work is needed, however, to fully explore the potential of this approach.