| By: | Lars Marius Garshol |
|---|---|
| Affiliation: | Ontopia |
| Email: | larsga@ontopia.net |
| Web: | http://www.ontopia.net |
|
This paper has since been replaced by a more recent and more thorough paper that also covers OWL and query languages: Living with topic maps and RDF.
For a concise statement of the relationship between RDF and Topic Maps, see Comparing Topic Maps and RDF.
The terms RDF, OIL, DAML, and topic maps all tend to be mentioned whenever technologies for the semantic web, knowledge management, or information management are being discussed. Finding someone who knows more than one of these well is almost impossible, however.
This paper sets out to change that, by providing quick introductions to each of the technologies, highlighting the similarities and differences between them. These technologies all come from very different backgrounds, and tend to be presented in very different ways, and yet on closer examination their anatomies turn out to be surprisingly similar.
The starting point of the paper is the observation that all these technologies provide a restricted set of mechanisms for making statements about the Universe of Discourse. The introductions to the technologies are done by describing how concepts such as 'thing', 'relationships between things', 'properties of things', 'types of things', 'names of things', 'kinds of things' and so on are represented within each technology.
After comparing the technologies it is shown how each of these technologies relate to one another and to what extent they build on each other or compete with each other. More importantly, the paper also shows how data can be moved from one representation to another, and how tools implementing the various technologies can be made to work together.
Lars Marius Garshol is currently Development Manager at Ontopia, a topic map software vendor. He has been active in the XML and topic map communities as a speaker, consultant and open source developer for a number of years.
Lars Marius has also been responsible for adding Unicode support to the Opera web browser. At the moment, he is completing his book on 'Developing XML Applications', to be published by Prentice-Hall in its Charles Goldfarb series later this year.
Lars Marius is one of the editors of the ISO Topic Map Query Language standard, and also co-editor of the Topic Map data model.
An old joke has it that "The nice thing about standards is that there are so many to choose between". This certainly applies to RDF, topic maps, DAML, and OIL, though whether it really is nice to have to choose among so many standards is very much in doubt. The main purpose of having a standard is to make it possible for data and applications to be interoperable, something that is much harder when the data and applications use proprietary technologies. This benefit is compromised, however, when a number of standards occupy the same space, as in this case.
This paper serves a number of purposes, but the most important of them is to help readers deal with this problem of standards with overlapping functionality. This is done by comparing the standards so that readers have a reasonable foundation for choosing the right standard for their needs, and by showing how data can be moved back and forth between the representations of the different standards.
Topic maps have a long and complicated history, beginning with the Davenport group, which in 1991 started a process to create a standard SGML DTD for software documentation. This group quite quickly spun off an offshoot called CApH (Conventions for the Application of HyTime) , one of whose tasks was to design an application for computerized back-of-book indexes. These indexes were intended to have one novel feature: it should be possible to merge them automatically. The ideas behind this application were what eventually became topic maps.
CApH worked on the concept for a long time, before topic maps was accepted by ISO's SGML working group as a new work item in 1996. ISO then spent another four years working on the standard before it was approved as ISO/IEC 13250:2000 in January 2000 ([ISO13250]. Topic maps then had the form of an SGML architecture based on HyTime. Work was later done by an informal organization known as TopicMaps.Org, which produced the XTM (XML Topic Maps) syntax for topic maps ([XTM1.0]). This was a reformulation of topic maps in XML syntax based on XLink. This syntax has since been accepted by ISO into ISO 13250 as an annex. The XTM syntax is used by nearly all topic map software today, while use of the original SGML syntax is rare.
Topic maps have many applications, but one of their main applications is that of solving the findability problem of information, that is: how to find the information you are looking for in large body of information. Topic maps can also be used for knowledge management, for web portal development, content management, and enterprise application integration (EAI). Topic maps are also being described as an enabling technology for the semantic web. (Note: throughout this section I will present what the proponents of each technology claim that it can do, and apply no critical analysis of my own, as that would be outside the scope of this paper.)
RDF (Resource Description Framework) [RDF] was developed by the W3C (World Wide Web Consortium) as part of its semantic web effort. RDF started as an extension of the PICS content description technology [PICS] (also a W3C technology), but was influenced by submissions from Microsoft and Netscape, and has evolved considerably beyond its beginnings. The first RDF working draft was released in October 1997, and the specification became a W3C Recommendation in February 1999. RDF is part of Tim Berners-Lee's effort to realize his vision of the Semantic Web.
As an information management technology RDF has a number of possible application areas. It is mainly intended for use in the semantic web, but it is also being described variously as a content management technology, a knowledge management technology, a portal technology, and also as one of the pillars of e-commerce.
DAML (DARPA Agent Markup Language) was created as part of a research program started in August 2000 by DARPA, a US governmental research organization. It is being developed by a large team of researchers, coordinated by DARPA. DAML is not defined by any standards body, but is published on daml.org, a site run as part of the DAML program.
DAML seems to be entirely focused on supporting the semantic web, though one would assume that it also has other uses. Given that DAML is much the same as OIL would seem that it too can be used to solve the findability problem, be used in e-commerce, and used in knowledge management.
OIL (Ontology Inference Layer) is an initiative funded by the European Union programme for Information Society Technologies as part of some of its reasearch projects. The work has been done by participants in these projects, and the resulting specification is a specification published by the reseach project.
OIL is obviously a semantic web technology, and according to the OIL FAQ OIL is intended to solve the findability problem, support e-commerce, and enable knowledge management.
Below is a table that compares the usage areas of these technologies.
| Area | TM | RDF | DAML | OIL |
|---|---|---|---|---|
| Findability | Yes | Yes | Yes | Yes |
| Portals | Yes | Yes | Yes | Yes |
| Content management | Yes | Yes | Yes | Yes |
| EAI | Yes | |||
| E-commerce | Yes | Yes | Yes | Yes |
| KM | Yes | Yes | Yes | Yes |
| Semantic web | Yes | Yes | Yes | Yes |
From this comparison it should be clear that the application areas of these technologies, as presented by their respective proponents, are more-or-less identical. The only difference being that RDF, DAML, and OIL are not presented as EAI technologies. This, however, does not mean that they cannot be used for EAI purposes. In short, those wishing to exchange information in any of these areas and using one of these standards are likely to find that exchange partners have chosen one of the other technologies. As this paper will show, however, this is not necessarily a problem.
The problem to be solved is that of making these four standards interoperate. At the lowest level that means being able to move data back and forth between the systems. A more ambitious goal is to be able to use software implementing different standards in the same production system, for example by using query languages or schema languages defined for one model with data represented in another. In this paper I will concentrate on moving data between the representations and not consider the issues of how to implement integrations in any depth.
This means that we will assume that there is an application A performing some function X for its users, based on topic maps, and another application B, also performing function X for its users, based on RDF. The problem to be solved is that of making A able to use B's data, and vice versa.
Before starting to look at specific ways to map data between representations it is useful to look at the criteria by which solutions can be judged. Below is a list of such criteria.
Does the solution require one of the models to be changed? It may be that one model can be altered slightly in order to provide for much better mapping between the models. Provided that the change is small, and that the resulting mapping is very good, such a solution is likely to the best possible, as it will effectively result in a harmonization of the standards. Such changes must be made very carefully, however, and the resulting mappings must be very good to justify the changes in the model.
Whether the solution is complete. If the source data can always be mapped to the target representation and then back again to the original representation, resulting in a representation that is logically equivalent to the original this criterion is fulfilled. This criterion is the most important criterion, but it is not an absolute must. Solutions that do well on the other criteria may still be better provided that data that cannot be mapped are rare.
How much effort is required to use the solution. That is, given a pair of applications A and B, how hard is it for someone, given an general implementation of the solution, and a set of source data, to actually produce the desired results? This criterion is very important, since it determines how the solution will be experienced by those who are going to use it. Solutions that are awkward to use run a substantial risk of not being accepted by the user community.
How much effort is required to implement the solution as a generally reusable piece of software. This criterion is important mainly because if implementation is too hard there are likely to be few implementations.
In general, there are two classes of approaches to mapping from one representation to another: schema-independent (or model-based) and schema-based mappings. The first class maps the model of the one representation directly to the model of the other, or it may model the one model inside the other. The result is that all data in one model can be mapped automatically into the other without further ado. The second class requires a mapping to be developed separately for every schema, but once that is done all conversions are automatic.
Of these two approaches, the model-based has an advantage in that it requires no effort to set up, which schema-based mappings do. It often has a disadvantage, however, in that the data in the target representation created by the mapping are often not in the desired form, and so require processing after the mapping. Both approaches can be complete, but model-based mappings are generally easier to implement. In short, one kind of mapping is not inherently superior to the other; one must examine individual proposals to find out which are the best.
There are two general approaches to implementing mappings between the models:
Static mappings are essentially conversions or exports: one takes a set of data in the source model and produces a complete mapping in the target model, whether serialized or in persistent storage.
Dynamic mappings are more sophisticated. They present an API through which the data from the source model can be seen dynamically as if they were stored in the target model. Any updates to the source data are instantly reflected through the mapping interface.
Which of these approaches that is the best depends on the needs of each particular application. The static mappings are by far the easier to implement, but in the situations where they are most appropriate the dynamic mappings are sufficiently more useful than the static ones that the effort of implementing them are worth it. Dynamic mappings are also the ones needed to achieve direct software integration.
In general, the exact form of the mapping between two data models is orthogonal to the issue of how it is implemented. Some mappings, however, may be difficult to implement efficiently as dynamic solutions.
Before we move on to look at specific mapping solution this section compares the different models, explaining the relationship between the different models.
The central notion in both RDF and topic maps is that there are things that we wish to make assertions about. Examples of such things may be the person 'Lars Marius Garshol', the company 'Ontopia', and this paper. In topic maps such things are represented by constructs called topics, in RDF by constructs called resources. At heart, these constructs are the same: digital symbols representing some well-defined thing.
In RDF each resource is represented by a single URI (Universal Resource Identifier) , which makes it clear exactly what the resource is. If the RDF model is making assertions about documents and files the URI will be that of the document or file, but many RDF models discuss abstract things, in which case the URI is just a symbolic identifier for the resource.
In topic maps, the things in the real world that topics represent are called their subjects. Topics may identify their subjects in several ways, for example by specifying the resource that is the subject of the topic by means of a URI. This corresponds exactly to an RDF resource representing a document or file. Topics can also have subject indicators, however, which are URIs referring to resources that indicate (to a human) what the subject of the topic is. This corresponds exactly to an RDF resource that represents an abstract concept. [this discussion is not sufficient: the interpretation of URIs is more complex than this]
Whether one used RDF or topic maps, one would generally assign the
same URIs to the three example things.
mailto:larsga@ontopia.net would be a reasonable URI for
the resource 'Lars Marius Garshol'. In a topic map this would be a
subject indicator, and not a subject address. For Ontopia,
http://www.ontopia.net would be the URI, and in a topic
map it would be a subject indicator. For this paper
http://www.ontopia.net/topicmaps/materials/tmrdfoildaml.html
would be the URI, and in a topic map this would be a subject address.
Below is a diagram that shows the representations of these three things in topic maps and RDF side by side for easy comparison.
Three things
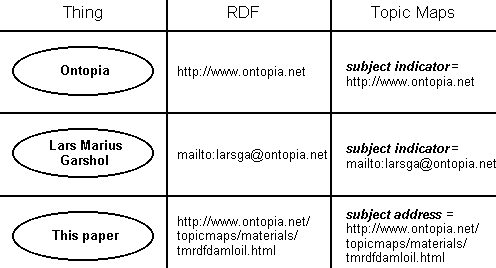
As can be seen, topic maps and RDF have the same central concept, but treat it slightly differently. In an RDF model there is no application-independent way of telling whether a resource is abstract or concrete. In topic maps, that can be seen by whether the topic has a subject address or a subject indicator.
The main difference between these models and XML is that XML does not have this concept. In XML there is no notion that each element necessarily represents some real-world 'thing', nor is there any procedure for declaring the identity of that 'thing'. For this reason the rest of the sections do not apply to XML, since they discuss the characteristics of these 'things', and as the 'things' themselves are missing from XML, so must necessarily their characteristics be.
When we create models of the world which contain things it is because we wish to make assertions about these things, and the main kind of assertion we wish to make is what relationships these things have with each other. RDF and topic maps both provide mechanisms for doing this, but these mechanisms are quite different.
In RDF resources can be assigned properties through the use of statements. These are simple triples, consisting of the resource being assigned a property, the property type (represented by a URI), and the property value, which can be a literal or a URI. The use of URIs as property values allows statements to express the relationships between things.
For example, to say that I am employed by Ontopia we could use this
simple RDF statement: (mailto:larsga@ontopia.net, employed-by,
http://www.ontopia.net.).
In topic maps the relationships between things can be expressed using associations. Associations are typed, like RDF statements, and the types are themselves topics. Any number of topics can play roles in an association, and their involvement in the association is defined by their association role type (which is also a topic). The relationship between me and Ontopia is perhaps best represented by an association of the type 'employed-by', where I play the role 'employee', and Ontopia the role 'employer'.
The diagram below shows what this relationship looks like in topic maps, using a graphical notation invented for the purpose.
One relationship in topic maps
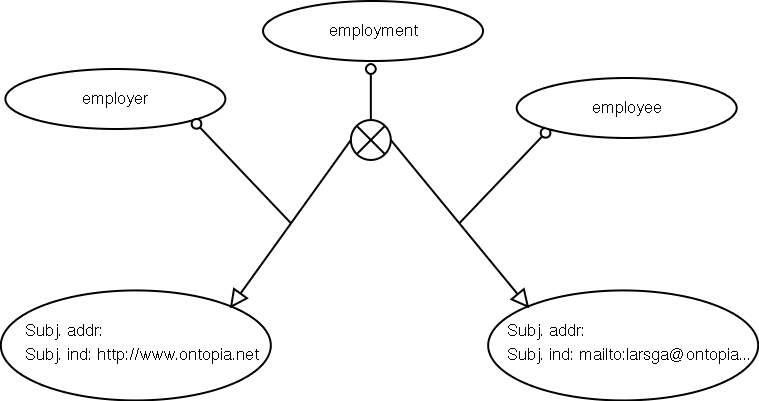
Below, the same relationship is shown in RDF. Obviously, the relationship is a lot simpler, but it is harder to extend, and it is also not clear to software with no knowledge of the schema that it is a relationship.
The same relationship in RDF
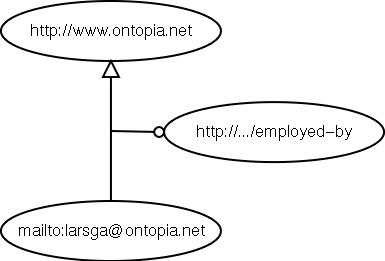
There are three major differences between how RDF and topic maps represent relationships:
The most obvious is the difference in the structure of the representation. RDF relates one thing to another, while topic maps can relate any number of things, and make it clear what involvement each has in the relationship. It is possible to achieve something similar with RDF, but that requires extra work, both in conceptualization and in implementation.
Another difference is that in topic maps relationships are inherently two-way. That is, you cannot say that I work for Ontopia without at the same time saying that Ontopia employs me. It is possible to traverse relationships backwards in RDF, and it is also possible to specify inverse properties, but this is not inherent in the way relationships are represented.
A third, and much more subtle, difference is that there is no way of knowing when an RDF statement is asserting a relationship between two abstract things and when it is saying that the one thing is really a resource that has information about the other, which is an abstract thing. Some statements also assign attributes to things, but it is possible to tell these apart, as they will have literals as objects instead of URIs.
In short, in topic maps you know that what is relationships and what is not, all relationships are two-way, and it is easier to represent complex relationships.
Another common wish in information modelling is to capture the attributes of the things being modelled. Attributes are pieces of information that may be attached to things, but which are not sufficiently important to be considered things in their own right.
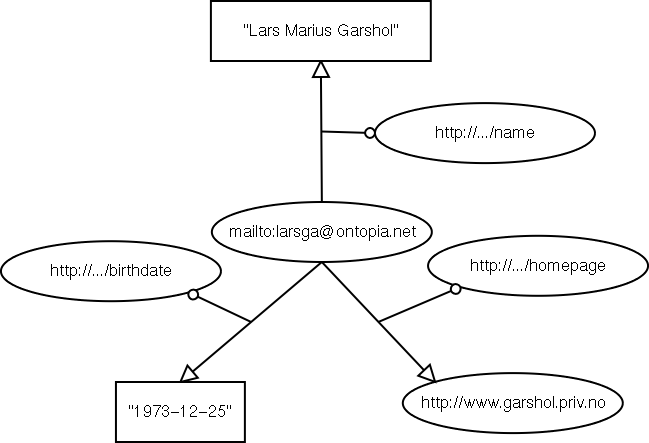
Some examples of attributes of the thing 'Lars Marius Garshol' are: my
name, my home page, and my birth date. In RDF, these things are simply
properties of the resource 'Lars Marius Garshol' and are encoded using
three statements: (mailto:larsga@ontopia.net, name, "Lars Marius
Garshol"), (mailto:larsga@ontopia.net, homepage,
http://www.garshol.priv.no), and
(mailto:larsga@ontopia.net, birthdate, "1973-12-25").
The diagram below shows what this would look like in RDF. Note how it is impossible to tell the assignment of names, metadata, and resources with more information apart from one another, and also from the statement in the previous section, that represented a relationship.
Three attributes in RDF
In topic maps this would look entirely different. Topic maps have a concept of occurrences, which are pieces of information relevant to a topic. Occurrences can either be resources external to the topic map, which are then represented by the URI of the resource, or they can be strings internal to the topic map. Occurrences are typed, the types being topics.
The natural way to represent my home page would be to give me an occurrence of type "home page", and to set the URI to "http://www.garshol.priv.no". My birth date would become an internal occurrence, of type "birth date", where the value was a string representing the date. My name, however, would not be an occurrence. Topic maps have a concept of topic names (which are really privileged occurrences), and so my name would be represented as a name.
Unfortunately, the author's drawing skills are insufficient to represent the differences between a topic, its name, and two kinds of occurrences, and so there is no diagram of this.
This is perhaps the point at which the differences between topic maps and RDF become most pronounced. There are three different classes of attributes involved here, and these are worth discussing separately:
Names can be represented in both topic maps and RDF, but only in topic maps is it possible for software with no knowledge of the schema to know which properties are names. The result is that in any interface topics can be represened by their names, something that requires schema knowledge in RDF. For generic applications this is very useful.
Simple properties are very similar in topic maps and RDF. A string is attached to the thing, and another thing tells you what the relationship of the string to the thing is.
Resources relevant to a thing are indistinguishable from relationships in RDF, both being represented by statements. In topic maps, the fact that the relationship is an occurrence relationship makes it clear that the resource contains more information about the thing. The occurrence type makes it clear what kind of information is found there.
Again topic maps are found to be higher-level than RDF and to contain more explicit semantics. This means both that it is easier to develop generic software for topic maps, and that conceptualization of topic map applications is easier, because some of the work has been done in the standard itself.
One of the most important pieces of information one generally wishes to record about things is of what kinds they are. For example, I am a person, while Ontopia is a company. This is very important information, and so both topic maps and RDF provide standardized means of representing it. In RDF, there is a standardized property called rdf:type which is used to represent the instance-of relationship between the class and the instance.
In topic maps this information is part of the model: each topic has a set of classes of which it is considered an instance. The information can therefore be represented directly. Topic maps also have a standardized association type for the class-instance relationship, which means that it is possible to represent this relationship with an association. Since this relationship is so fundamental most topic map implementations represent it as a property of topics, however.
This is in fact the area where topic maps and RDF have most in common, and rdf:type is as good as identical to the topic map notion of class-instance.
It is often useful to be able to attach information about the context of the relationships and attributes of things. This context information may state that "this characteristic is only valid in a certain context", or provide useful metadata about the characteristic. RDF has no notion of such contexts, although by introducing anonymous resources in property assignments context information can be attached to the assignments. This is somewhat awkward, however.
In topic maps, such contexts are known as scopes. Scopes consist of sets of topics which define the context of validity, and can be attached to names, occurrences, and associations. This feature can be quite useful. For example, what if one wishes to make a multilingual information system where information may be available in many languages? In RDF this can be handled by defining separate properties for, say, names and definitions of concepts in each language. This is awkward and obscures the commonalities of names and definitions. It also obscures the fact that the differences between the various properties is one of context, and makes it harder to extend the schema. In topic maps this can be handled by using language as one axis of scope. Names are already first-class constructs to which scope can be attached, and definitions can be made occurrence types.
The main differences between topic maps and RDF in this area is that context is much easier to work with in topic maps, and that generic software can know how contexts are represented in each application. In fact, the Ontopia Omnigator ([Omnigator], is a generic topic map browser, which can analyze the scopes used in a topic map, and allows the user to set a context to be used for filtering the topic map as it is displayed. [screenshot of filter page?]
[Pepper01] provides an in-depth discussion of scope in topic maps, and has much useful information on the applications of scope.
Reification is a technique that originated in artificial intelligence, and the term quite literally means "thingification". This is also essentially what it means: to turn objects we wish to speak of into "things", so that we can make assertions about them. This is essential because before objects become things we cannot speak of them.
To take an example: what if wanted to make the statement that the name "Ontopia" is of Greek origin? In the topic map, the topic "Ontopia" has a name, which is "Ontopia", but we cannot create an association between this name and the Greek language, because associations only connect topics. The solution is to reify the name by making a topic that represents it, and then associate that topic with Greek.
The only problem with this solution is that it is impossible for software to know that subject of the topic "Ontopia's-name" is the name of the topic "Ontopia". This can be solved by giving the name an ID (which is possible in the XTM syntax) and then making the subject indicator of the "Ontopia's name" topic refer to this ID. This lets software know what the relationship between this topic and the topic name is.
RDF has a similar notion of reification, although it is used slightly differently there. This author is not sufficiently familiar with RDF to be able to compare the use of reification in RDF with its use in topic maps.
Unlike RDF and topic maps DAML is not a data model; instead, it is a schema language that can be used to constrain and describe data following the RDF data model. To put it another way: DAML is an RDF schema language. RDF already has a schema language, called RDF Schema [RDF-Schema], and DAML is an extension of this language. Note that DAML also extends the RDF syntax, and that DAML files cannot necessarily be parsed with RDF parsers.
The value of DAML is thus that it allows one to describe RDF data, and so makes it possible to add more semantics to the data. As one of the major differences between topic maps and RDF is that topic maps provide more information about their own semantics this is interesting as a possible way of narrowing the gap between RDF and topic maps. In general, what DAML adds to RDF Schema is additional ways to constrain the allowed values of properties, and what properties a class may have. In addition, it provides some properties that can be truly useful to generic software, which are:
daml:samePropertyAs, which makes it possible to say that two RDF properties from different schemas are in fact the same property.
daml:inverseOf, which can be used to say that one RDF property is the inverse property of another. This means that together the two properties describe a relationship both ways, and so provides some of the two-way semantics of topic map associations. This mechanism does not work very well for relationships that are not binary, however.
daml:TransitiveProperty, which is a property type which other property types can subclass to make it clear that they are transitive. An example of a transitive property is 'larger than'. If we know that 'larger than' is transitive and that A is larger than B and that B is larger than C, we also know that A is larger than C. This knowledge can be very useful indeed.
In short, DAML strengthens the RDF schema language, and adds a little bit of semantics on top. The semanics are mainly things topic maps already have, apart from the ability to specify that a relationship is transitive. This ability is really a poor man's inference engine, and any inference engine, for RDF or for topic maps, will provide capabilities far beyond what this property provides.
OIL is very similar to DAML in that it, too, is an extension of RDF Schema, and the capabilities of the two languages are very similar. They are not entirely the same, however, despite the fact that the latest release of DAML is called DAML+OIL. The proponents of OIL claim that OIL has some desirable properties and capabilities that DAML does not, but these are not very relevant to the issue discussed in this paper, and will therefore not be discussed here.
To compare with topic maps, there is no standardized schema language for topic maps, although one is under development ([TMCL]). As for the semantics added by DAML to RDF, topic maps already have most of these. Stating that two association types or occurrence types are the same is done by merging them in topic maps. There is no need for an inverse of relationship, since all relationships are multidirectional in topic maps. The ability to say that a relationship is transitive, however, is missing from topic maps, and would make a useful addition.
To help readers get an overview of the models presented so far, this section shows the example model about the author and Ontopia using the different syntaxes of topic maps and RDF.
Below is shown the example model in LTM syntax ([LTM1.1]). The characteristics of the the typing topics are left out for clarity.
The model in LTM
[lmg : person = "Lars Marius Garshol"
@"mailto:larsga@ontopia.net"]
{lmg, homepage, "http://www.garshol.priv.no"}
{lmg, birthdate, "1973-12-25"}
[ontopia : company = "Ontopia"
@"http://www.ontopia.net"]
employed-by([ontopia] : employer, [lmg] : employee)
Below are shown the corresponding RDF triples.
The model in RDF triples
{mailto:larsga@ontopia.net,
http://psi.ontopia.net/example/employed-by,
http://www.ontopia.net}
{mailto:larsga@ontopia.net,
http://psi.ontopia.net/example/name,
"Lars Marius Garshol"}
{mailto:larsga@ontopia.net,
http://www.w3.org/1999/02/22-rdf-syntax-ns#type,
file://lmg.ltm#person}
{http://www.ontopia.net,
http://www.w3.org/1999/02/22-rdf-syntax-ns#type,
file://lmg.ltm#company}
{mailto:larsga@ontopia.net,
http://psi.ontopia.net/example/birthdate,
"1973-25-12"}
{mailto:larsga@ontopia.net,
http://psi.ontopia.net/example/homepage,
http://www.garshol.priv.no}
{http://www.ontopia.net,
http://psi.ontopia.net/example/name,
"Ontopia"}
RDF and topic maps have the same central concept, which I have here called 'thing'. They have entirely different notions about how characteristics are assigned to these 'things', however, and their ideas about how to establish the identities of the 'things' are also different. In RDF statements, in the form of (subject, property, object) triples, are the only way of assigning characteristics, while in topic maps topics may have names, occurrences, and participate in associations.
In RDF, the URI of the resource identifies it. In topic maps, the topic may have a URI that points to the resource that is the topic, and it may have any number of URIs that point to resources that explain what the topic is.
In a very real sense this makes RDF substantially lower-level than topic maps, and means that it is impossible to make sense of RDF models without knowledge of their schema to the extent that one can, for example, display the data in a user-friendly fashion. With topic maps, however, this is possible, because of the higher level of abstraction.
DAML and OIL use the same data model as RDF, which they do not enrich, and to which they contribute very little in the way of semantics, and so no further consideration needs to be given to them.
In the table below each row shows a possible correlation of terms between topic maps and RDF. This table is neither complete nor exact, but should provide a useful summary of the model comparison. Note that a very useful, and sadly overlooked, source on information about topic map terminology is annex B of [XTM1.0].
| Topic map term | Relationship | RDF term |
|---|---|---|
| Topic map | comparable to | RDF graph |
| Topic | comparable to | Resource |
| Subject | comparable to | Resource |
| Resource | comparable to | Network-retrievable resource |
| Non-addressable subject | comparable to | Non-network-retrievable resource |
| Association | kind of | Statement |
| Occurrence | kind of | Statement |
| Name assignment | type of | Statement |
| Class of topics | comparable to | Class |
Now that we know what the relationship between the two models is we can start considering the question of how to move data back and forth between the two representations.
Before we move on to consider possible solutions we will look at the work already done in this area, and consider it in the light of the criteria presented in an earlier section.
The first publicized proposal for integrating RDF and topic map data was [Moore01]. This paper does a number of different things, and we'll go through them one by one.
The first thing it does is to represent RDF models using topic maps. This is done very simply by defining subject indicators for the concepts of RDF statements, subjects, properties, and objects. Each RDF statement then becomes an association of type RDF statement, where the subject, property, and object play the roles defined by the subject indicators already mentioned.
This provides a straightforward means of representing RDF in topic maps, although it leaves some questions open. For example, the RDF resources presumably become topics, but nothing is said about what happens with their URIs. Do they become subject addresses or subject indicators? It is clear that this mapping leaves a number of things to be desired also from a practical point of view. In Moore's defense it must be said that it does not seem to have been intended to be more than an academic exercise to show that topic maps are flexible enough to model RDF, and so I will leave it at that.
The next step taken in the paper is to model topic maps using RDF. Here RDF properties are defined for the various topic map constructs, and topic maps are represented accordingly. One notable aspect is that names, for example, are represented using an anonymous resource, in order that scope, foer example, may be attached to it. The model is not complete, however, as variant names are not handled, and again the question of how to handle subject addresses and subject indicators is left open. Again, however, Moore's text indicates that he intends merely to demonstrate that RDF can represent topic maps, and not to create a practical solution.
The last step taken in the paper is to propose a model-to-model mapping from RDF to topic maps, and this is the real purpose of the paper. The model-to-model mapping equates RDF model with topic map, and topic with resource. This is generally accepted, and this paper takes the same approach. The URIs of RDF resources are equated with the subject indicators of topics in topic maps, leaving unanswered the question if the URIs of some RDF resources may not also be subject addresses.
Finally, RDF statements are compared with associations in topic maps, and the paper proposes that statements can be mapped to associations if the property becomes the association type, and fixed, pre-defined topics are used to represent the subject and object roles in the association. This works, but can only be the first stage of a mapping, since, as we have already demonstrated, RDF statements can have a number of different topic map equivalents, not just associations.
Moore does not stop here, however, but proceeds to propose that the topic map model be extended with the concepts of "arc" and "association template". The paper leaves the workings of these somewhat unambigious, so the question of whether these concepts suffer from the same problem as the mapping to associations is unclear.
To summarize, Moore's work is interesting, and serves to highlight a number of interesting points, but it is not the final word on this issue. The author himself describes it as a "first positional paper introducing the concepts", and this is a fair summary.
Another interesting proposal is the one presented in [Lacher01]. This paper presents a method for mapping topic map data into RDF data, based on the topic map data model proposal presented in [PMTM4]. In fact, the approach presented is an RDF schema that directly represents the [PMTM4] model using RDF statements corresponding to the constructs found therein. This approach works, and is, as claimed by the authors, complete and reversible, but the resulting RDF data are very awkwardly represented.
[Lacher01] does not provide any serialized examples of topic maps mapped to RDF, so it is little difficult to evaluate this proposal fully, but some properties of the mapping are clear:
The mapping uses an RDF schema defined by itself, so that to make use of the data after mapping them, RDF applications must either understand the proposed schema or do further processing.
The representation of topic map data in the proposed RDF schema is highly awkward, in that retrieving the base names of a topic, for example, requires non-trivial queries to be performed on the resulting RDF model.
The problem with subject addresses versus subject indicators is not handled at all.
In short, this proposal is incomplete, in that it only considers mapping RDF to topic maps, and also in that the resulting RDF is relatively awkward to work with.
[Ogievitsky01] also considers the mapping of topic map data to RDF, and takes an approach similar to that of [Lacher01]. [Ogievitsky01] is also based on [PMTM4], but departs from it in several respects. It also uses a different RDF Schema from [Lacher01].
There are several interesting aspects of Ogievetsky's proposal:
If the topic has a subject address, that becomes the URI of
the RDF resource used to represent it. If it has no subject address an
ID is generated for it and assigned with rdf:ID. Subject
indicators become properties of the resource. This is reasonable,
although whether the semantics of RDF's 'resource' and the 'subject
constituting resource' are the same is unclear. There may be
applications that wish to see this done in other ways.
The class-instance relationship in topic maps is represented
using rdf:type. This is clearly the right
solution.
The associations become resources as well, of which the participating topics are properties. This seems rather backwards given that the associations certainly assert properties of the resources.
Names and occurrences also become resources, of which the topic resource is a property, as is the name string, occurrence string, or occurrence resource. Again, this seems rather backwards as the name of a resource is a property of the resource.
Scope is represented as a property of the topic characteristic resources, which makes good sense.
In short, Ogievetsky's proposal is incomplete, in that it only considers going from topic maps to RDF, and it produces RDF output that is, again, awkward to work with. On the other hand, the treatment of the topic maps to RDF mapping is relatively complete.
To summarize, the work done on RDF and topic map integration to date is incomplete, in that the only in-depth proposals concern mode-based mappings of topic map data to RDF. The only work that is done on comparing the models is unsatisfactory. Also, hardly any of the problematic issues have been addressed, and few, if any, attempts have been made at separating constructs that are obviously very similar across the models from constructs that obviously very different.
As shown in the previous section RDF models consist of statements in the form of triples, and the correct representation of an RDF statement in a topic map can be any of a number of possible constructs in a topic map. The table below enumerates the possible appropriate mappings for an RDF statement in topic maps. The subject, property, and object columns, show what each corresponds to in topic map terms.
| Statement | Subject | Property | Object |
|---|---|---|---|
| Association | Role playing topic | Association type (and role types) | Role playing topic |
| Occurrence | Topic | Occurrence type (and scope) | Resource |
| Base name | Topic | Scope | Base name value |
| Variant name | Topic | Scope (and base name) | Variant name value |
| Subject indicator | Topic | URI prefix, if any | Subject indicator URI |
| Instance of | Topic | Instance of association | Topic |
The obvious conclusion to be drawn from this is that a generalized mapping from RDF to topic maps that will work for any RDF model is not possible. A person with knowledge of the RDF schema, however, can construct an appropriate mapping. This is possible because while statements can correspond to many different things, each property corresponds to one, and only one, of these alternatives.
To make this discussion more concrete we will use an example RDF model to demonstrate the principles. This is the RDF version of WordNet found at http://www.semanticweb.org/library/, in which dictionary information can be found in RDF form. This dictionary is based around concepts with numbered IDs, and these concepts have word forms that can be used to refer to them, glossary definitions, references to more specialized concepts, and also references to similar concepts. Below is given the set of RDF statements pertaining to one word in WordNet.
A set of WordNet statements
1 : {http://www.cogsci.princeton.edu/~wn/concept#200399152,
http://www.w3.org/1999/02/22-rdf-syntax-ns#type,
http://www.cogsci.princeton.edu/~wn/schema/Verb}
2 : {http://www.cogsci.princeton.edu/~wn/concept#200399152,
http://www.cogsci.princeton.edu/~wn/schema/wordForm,
'understand'}
3 : {http://www.cogsci.princeton.edu/~wn/concept#200399152,
http://www.cogsci.princeton.edu/~wn/schema/wordForm,
'realize'}
4 : {http://www.cogsci.princeton.edu/~wn/concept#200399152,
http://www.cogsci.princeton.edu/~wn/schema/wordForm,
'see'}
5 : {http://www.cogsci.princeton.edu/~wn/concept#200399347,
http://www.cogsci.princeton.edu/~wn/schema/hyponymOf,
http://www.cogsci.princeton.edu/~wn/concept#200399152}
6 : {http://www.cogsci.princeton.edu/~wn/concept#200399152,
http://www.cogsci.princeton.edu/~wn/schema/glossaryEntry,
'perceive mentally, as of an idea; "Now I see!";
"I just can\'t see your point"'}
These are the RDF statements that apply to the concept with the ID 200399152. Below I'll explain the significance of each statment.
This statements says that this concept is an instance of the type "Verb"; that is, that it is a verb.
This statement says that one word form which can be used to refer to this concept is "understand".
This statement says that one word form which can be used to refer to this concept is "realize". This implies that "understand" and "realize" can be used as synonyms for the same concept. (Note that it is fully possible for these words to also refer to different concepts.)
This statement provides an additional word form: "see".
This statement says that the concept with ID
200399152 is a more specialized form of this
concept.
Finally, this statement provides the glossary definition of the concept.
Now that we understand the RDF application we are ready to start mapping it to a topic map. As there are only four RDF properties involved, this should not be too hard. Below is described how to map each of these properties into topic map constructs:
rdf:type: Mapping this predicate is easy, since it asserts that the subject is an instance of the object, both of which are identified by their subject indicators.
wordForm: This predicate is also easy. It assigns a name to the subject, which is identified by its subject indicator.
hyponymOf: This predicate asserts a "hyponym of" association between the subject and the object. The subject plays the "specific term" role, while the object plays the "general term" role.
glossaryEntry: This predicate assigns an occurrence of type "glossary entry" to the subject.
This means that we are now ready to actually perform the mapping and turn the entire WordNet RDF model into a topic map. I have developed an XML syntax for describing mappings from RDF to topic maps, and made a proof-of-concept implementation of this in Jython, using the Ontopia Topic Map Engine. The mapping file describes the mapping of each RDF property using a syntax that is essentially a templated version of the XTM 1.0 syntax.
This is done by writing a mapping file in XML which describes how the mapping is performed. The mapping file for the WordNet example can be seen below.
The WordNet mapping file
<rdf-to-tm>
<property uri="http://www.w3.org/1999/02/22-rdf-syntax-ns#type">
<instanceOf/>
</property>
<property uri="http://www.cogsci.princeton.edu/~wn/schema/wordForm">
<baseName/>
</property>
<property uri="http://www.cogsci.princeton.edu/~wn/schema/glossaryEntry">
<occurrence>
<instanceOf>Glossary entry</instanceOf>
<resourceData/>
</occurrence>
</property>
<property uri="http://www.cogsci.princeton.edu/~wn/schema/hyponymOf">
<association>
<instanceOf>Hyponym of</instanceOf>
<member>
<roleSpec>Specific term</roleSpec>
<subject/>
</member>
<member>
<roleSpec>General term</roleSpec>
<object/>
</member>
</association>
</property>
</rdf-to-tm>
Each property element in the mapping file defines how to
map an RDF property into topic map constructs. The URI of the subject
resource always becomes the subject indicator of a topic, unless
otherwise noted in the mapping file (there are no examples of this
here). The templates can also be enriched beyond what is shown here;
for example, the scope of base names, occurrences, and associations
can be specified in the mapping file.
By feeding this mapping file together with the WordNet RDF snippet quoted above into our RDF-to-topicmap mapper a topic map equivalent to the one shown below (in LTM syntax [LTM1.1]) is created. The example is not shown in XTM syntax, as that would take up quite a bit of space, and be much less readable.
The result of the mapping
[understand : verb = "realize"
= "understand"
= "see"
@"http://www.cogsci.princeton.edu/~wn/concept#200399152"]
{understand, glossary, [[perceive mentally, as of an idea; "Now I see!";
"I just can't see your point"]]}
hyponym-of([understand] : general, [perceive] : specific)
This topic map has one topic, understand, of type
verb, with three base names, and a subject indicator.
(This is what is contained in the square brackets.) That topic also
has an occurrence, of type glossary, with the text given.
Finally, there is an association, of type hyponym-of,
where the topic understand plays the role of the general
concept, while the topic perceive plays the role of the
specific concept.
This solution is easy to configure, easy to use, and produces topic map data that is of quality comparable to that of topic maps created as topic maps to begin with. Given an existing topic map engine and an RDF parser the solution is also easy to implement. The Jython implementation is 300 lines of code. (The source is not given here for reasons of space.)
This solution has some weaknesses, admittedly, the most important being that it does not handle RDF property assignments that are indirect. That is, assignments that use anonymous resources. This could be because they use RDF collections, or because one wants to reify the property assignment. A second weakness is that in some cases it may be desirable to map RDF properties in more than one way, for example based on the type of the subject or information attached to the property assignment via reification. (Scope, for example, might well depend on reification.)
I have been unable to investigate these issues through a combination of lack of RDF expertise, and a lack of real-world examples which actually make use of these features. Most likely, the way to handle these cases would be to allow the mapping file to perform RDF queries using some RDF query language in order to produce the input data to the mapping. I hope to be able to explore this in later work.
One way of mapping from topic maps to RDF is that of defining the topic map model using an RDF schema, and implementing something that can export topic maps in this RDF form. This, as already mentioned, is the approach taken by [Lacher01] and [Ogievitsky01]. As was also mentioned above, both of these use schemas that represent topic map data in a relatively awkward form, making the resulting data difficult to use.
In [Garshol01a] can be found an abstract model for topic maps defined using the infoset model approach first adopted by the W3C for the XML Information Set ([Cowan01]). This model is quite straightforward and an RDF Schema for it yields RDF models that are considerably easier in use than the ones already proposed. Below is shown an excerpt of the schema, to give an indication of how it looks.
RDF Schema for the infoset model
<!-- EXCERPT ONLY! --> <!-- ========================================================================= TOPIC MAP OBJECT ========================================================================== --> <rdfs:Class ID="TopicMapObject <rdfs:comment>The class of all objects that may be found in topic maps.</rdfs:comment> </rdfs:Class> <rdfs:Property ID="source-locators"> <rdfs:domain resource="#TopicMapObject"/> <rdfs:range resource="#LocatorSet"/> </rdfs:Property> <!-- ========================================================================= TOPIC MAP ========================================================================== --> <rdfs:Class ID="TopicMap"> <rdfs:comment>The class of topic maps.</rdfs:comment> <rdfs:subClassOf resource="#TopicMapObject"/> </rdfs:Class> <rdfs:Property ID="base-locator"> <rdfs:domain resource="#TopicMap"/> <rdfs:range resource="#Locator"/> </rdfs:Property> <rdfs:Property ID="topics"> <rdfs:domain resource="#TopicMap"/> <rdfs:range resource="#TopicSet"/> </rdfs:Property> <rdfs:Property ID="associations"> <rdfs:domain resource="#TopicMap"/> <rdfs:range resource="#AssociationSet"/> </rdfs:Property> <!-- ========================================================================= TOPIC ========================================================================== --> <rdfs:Class ID="TopicMap"> <rdfs:comment>The class of topics.</rdfs:comment> <rdfs:subClassOf resource="#TopicMapObject"/> </rdfs:Class> <rdfs:Property ID="classes"> <rdfs:domain resource="#Topic"/> <rdfs:range resource="#TopicSet"/> </rdfs:Property> <rdfs:Property ID="basenames"> <rdfs:domain resource="#Topic"/> <rdfs:range resource="#BaseNameSet"/> </rdfs:Property>
A mapping from topic maps to this schema would be quite
straightforward to implement. The URIs of all RDF resources would be
one of their [source locator] URIs, and those without
source locators would be given auto-generated IDs. Below is shown what
the example topic map might look like when exported to this RDF model.
The example topic map in RDF
<rdf:RDF xml:lang="en"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns="http://psi.ontopia.net/infoset#">
<TopicMap rdf:about="#id0"/>
<Topic rdf:about="#lmg">
<baseName>
<BaseName rdf:about="#id1">
<value>Lars Marius Garshol</value>
</BaseName>
</baseName>
<subjectIndicator rdf:resource="mailto:larsga@ontopia.net"/>
<occurrence>
<Occurrence rdf:about="#id2">
<instanceOf rdf:resource="#homepage"/>
<locator rdf:resource="http://www.garshol.priv.no"/>
</Occurrence>
</occurrence>
<occurrence>
<Occurrence rdf:about="#id3">
<instanceOf rdf:resource="#birthdate"/>
<value>1973-12-25</value>
</Occurrence>
</occurrence>
</Topic>
<Association rdf:about="#id4">
<instanceOf rdf:resource="#employed-by"/>
<role>
<AssociationRole rdf:about="#id5">
<instanceOf rdf:resource="#employee"/>
<player rdf:resource="#lmg"/>
</AssociationRole>
</role>
<role>
<AssociationRole rdf:about="#id6">
<instanceOf rdf:resource="#employer"/>
<player rdf:resource="#ontopia"/>
</AssociationRole>
</role>
</Association>
</rdf:RDF>
The example is rather long, and the syntax somewhat verbose, but the basic principles should be clear. This approach is simpler than the ones proposed in [Lacher01] and [Ogievitsky01], but the resulting RDF is still not of the kind one can would use directly in RDF applications.
The purpose of this section has mainly been to illustrate how topic maps could be modelled more straightforwardly based on the infoset approach than on [PMTM4]. The purpose achieved we move on.
The other way of mapping from topic maps to RDF is to not implement topic maps as an RDF application, but instead to allow topic map data to be mapped to RDF using mapping declaration. This allows us to generate RDF data that is more convenient in use, and also allows us to produce RDF that can be used by RDF applications which know nothing whatever of topic maps.
Describing schema-based mapping from topic maps to RDF is somewhat harder than going from RDF to topic maps, mainly because in RDF the mapping depends on the property alone, while in topic maps things are much more complex. To be able to build mapping specifications we need a language that lets us express how to extract information from topic maps in a concise way. To put it another way: we need a query language. Given that ISO TMQL is not yet finished the obvious choice is tolog [Garshol01b]. (The version of tolog used here has been updated somewhat since the publication of the referenced paper.)
Again, the mapping specification will be an XML document, describing how to generate RDF statements from topic map data. Below is shown such a specification for the example topic map.
Mapping the example topic map to RDF
<tm-to-rdf>
<generator> <!-- 1 -->
<query>employed-by($A : employee, $B : employer)</query>
<subject>$A</subject>
<property>http://psi.ontopia.net/example/employed-by</property>
<object>$B</object>
</generator>
<generator> <!-- 2 -->
<query>instance-of($A, person), has-name($A, $B)</query>
<subject>$A</subject>
<property>http://psi.ontopia.net/example/name</property>
<object>$B</object>
</generator>
<generator> <!-- 3 -->
<query>instance-of($A, $B)</query>
<subject>$A</subject>
<property>http://www.w3.org/1999/02/22-rdf-syntax-ns#type</property>
<object>$B</object>
</generator>
<generator> <!-- 4 -->
<query>has-occurrence($A, birthdate, $B)</query>
<subject>$A</subject>
<property>http://psi.ontopia.net/example/birthdate</property>
<object>$B</object>
</generator>
<generator> <!-- 5 -->
<query>has-occurrence($A, homepage, $B)</query>
<subject>$A</subject>
<property>http://psi.ontopia.net/example/homepage</property>
<object>$B</object>
</generator>
</tm-to-rdf>
In this example the RDF model is produced by joining the results of all the generators into a single RDF model. A set of RDF statements is produced from each generator by first executing the query, and then for each match in the query resulting instantiating a statement by filling in the attribute values. Note that variables and constants can appear in any of the three statement template elements.
Variable references are replaced by one of the subject indicators of
the topic held in the variable. It is possible to use a
uri attribute on the statement template elements to
override this, and use source locators (see [Garshol01a]), subject addresses, or generated object IDs
instead. Base names and occurrences are represented either by their
string values, or by the URI of the occurrence resource.
If we use the setup given above on the example topic map the result will be the RDF model shown below. The numbers before the RDF triples here refer to the number of the generator statement that caused them to be generated.
Topic map to RDF conversion result
1 : {mailto:larsga@ontopia.net,
http://psi.ontopia.net/example/employed-by,
http://www.ontopia.net}
2 : {mailto:larsga@ontopia.net,
http://psi.ontopia.net/example/name,
"Lars Marius Garshol"}
3 : {mailto:larsga@ontopia.net,
http://www.w3.org/1999/02/22-rdf-syntax-ns#type,
file://lmg.ltm#person}
3 : {http://www.ontopia.net,
http://www.w3.org/1999/02/22-rdf-syntax-ns#type,
file://lmg.ltm#company}
4 : {mailto:larsga@ontopia.net,
http://psi.ontopia.net/example/birthdate,
"1973-25-12"}
5 : {mailto:larsga@ontopia.net,
http://psi.ontopia.net/example/homepage,
http://www.garshol.priv.no}
This solution is easy to implement (given a tolog query processor, of course), easy to use, and produces RDF data that can be used directly by RDF applications, and which may conform to any RDF schema. Its main weakness is that support for generating more complex RDF statements is missing, and this should be added in future versions.
This paper has compared the data models and features of RDF, topic maps, DAML, and OIL, and found that RDF, DAML, and OIL all share a data model and are a single family of specifications, while topic maps, on the other hand, are quite different. It is also found that some concepts are near-identical across the two data models, while others are very substantially different.
Based on the comparison of the models we have shown that a schema-independent mapping from RDF to topic maps is impossible, since topic maps are at a higher level of abstraction. We have proposed a solution for schema-based mappings from RDF to topic maps, and shown that it can produce good results, even if it does not support all the subtleties of the RDF data model. We have suggested how the solution could be extended to provide such support.
We have examined earlier attempts at schema-independent mappings from topic maps to RDF, and found them awkward in use. We have proposed our own solution, and found it to be slightly better, but not really sufficient. The conclusion to be drawn from this seems to be that schema-independent mappings can be useful, but that they are not the best solution in this case.
We have proposed a method for schema-based mappings from topic maps to RDF, and shown that this can produce good results, although it does not support all aspects of the RDF data model.
At a higher level, the conclusion in this paper is that moving data back and forth between topic maps and RDF is possible, but that schema-based mappings are necessary. The models are also found to have substantially different features, and to occupy different levels of abstraction. Conclusions about significance of these differences are left for the reader to draw.
It is hoped that this paper represents another step forward in the effort to create and document an understanding of the relationship between topic maps and RDF. Further steps are admitted to be necessary, and it is hoped that at least one paper to be presented at XML Europe 2002 will contain a paragraph concluding that "the analysis and proposals presented in [Garshol01], while useful, are incomplete" and go on to remedy that.
Thanks to Steve Pepper, for help on improving the prose presentation of the paper.
Thanks to Geir Ove Grønmo, for corrections of some omissions throughout the paper.
Thanks to David Allsopp, for answering some of my questions on RDF and DAML.
Thanks to Nikita Ogievetsky, Martin Lacher, and Graham Moore for discussing their solutions with me.
Thanks to Aaron Swartz and Eric Miller for a very constructive discussion, which was, sadly, too close to the deadline (through the author's own fault) to have much as impact on the paper as it should have had.