| By: | Lars Marius Garshol |
|---|---|
| Affiliation: | Ontopia |
| Email: | larsga@ontopia.net |
| Web: | http://www.ontopia.net |
|
This paper shows how topic maps can address the limitations of traditional content management systems while building on their strengths. The term ITMS (Integrated Topic Management System) is coined for a content management system based on topic maps, and the paper shows what is necessary to build such systems, as well as what benefits they bring.
The use of the WebDAV protocol to layer topic maps over content stores is also considered, and an abstract topic map-to-content store protocol is sketched, which corresponds very closely to WebDAV.
The paper assumes a basic knowledge of topic maps. Those unfamiliar with topic maps are recommended to read an introduction such as [Pepper02] first.
Lars Marius Garshol is currently Development Manager at Ontopia, a leading topic map software vendor. He has been active in the XML and topic map communities as a speaker, consultant, open source developer, and technology creator for a number of years. He has worked with content management using SGML and XML since 1997, and using topic maps since 1999.
Lars Marius has also been responsible for adding Unicode support to the Opera web browser. His book on 'Definitive XML Application Development', was published by Prentice-Hall in its Charles Goldfarb series earlier this year. Lars Marius is one of the editors of the ISO Topic Map Query Language standard, and also co-editor of the Topic Map data model. He also chairs the OASIS GeoLang TC.
The traditional CMS (Content Management System) has succeeded in solving some of the problems of managing content in a multi-user environment, but several aspects of such systems leave much to be desired. In particular, the organization of the information within a CMS has generally been its weakest point. CMS systems have tended to use ad-hoc models for organizing their content, which has made their functionality less flexible than it might otherwise have been. In part for the same reason maintenance of the content has been made unnecessarily difficult.
Topic maps [ISO13250] provide just what is needed: a model for organizing and describing information resources that is well designed, stable, and infinitely flexible. Adopting topic maps as the organizing principle of the CMS instead of an ad-hoc solution simplifies implementation of the CMS while greatly improving its utility and usability. The rest of this paper will be devoted to exploring how CMSs may make use of topic maps to build ITMSs.
The term Content Management System is used very broadly and has traditionally had a different meaning within the SGML/XML community than outside it. Within the SGML/XML community it has been common to consider a CMS to be a system which can store and manage content for the purposes of editing and authoring. Publishing has been considered a separate process, which the CMS may or may not support.
In the general IT community, however, a CMS is primarily thought of as a system facilitating the publishing of content that also supports the necessary authoring and editing. Some have coined the term DMS (Document Management System) for what the SGML/XML community calls a CMS [Bronder02]. It seems likely that the SGML/XML community's emphasis on separating structure from presentation (or abstraction from rendition) is responsible for this difference in perception.
Since the author is a self-declared SGML/XML-head and since the paper is being presented at an SGML/XML conference, we will continue to use the term CMS in the meaning it usually has within this community. The results presented in the paper are believed to also apply to the more publishing-oriented form of CMS, however.
Classic CMS systems have commonly had the following functionality:
Authoring environment. All CMSs provide some form of user interface through which authors and editors may access and modify their content. This environment is often composed of several different, and even independent, applications.
Structured storage. All CMSs organize content into content objects (minimal storage components) and provide some structure within which these objects can be categorized and later found. This has typically been augmented by metadata schemes of various kinds.
Concurrency management. Most CMSs support some way of dealing with the problem that users may cause conflicts by modifying the same content at the same time. This may be done through the tried-and-true metaphor of check-in, check-out, or by other means.
Access control. Most CMSs support authentication of users and the assignment of different access rights to different groups of users.
Versioning. Most CMSs have some level of support for storing each version of a content object throughout its history together with descriptions of the changes made to each version. Some CMSs also support configuration management, in the sense that they can reproduce the state of the entire system at a particular time.
Workflow. Many CMSs are integrated with workflow engines to allow the management of content objects in the CMS to be done through a formal workflow.
Publishing. Presumably all CMSs have in some way been integrated with a publishing system in order to allow the managed content to be used, but not all CMS products include a publishing component.
Of this functionality, the weakest point has tended to be the storage structure and the way in which content is organized within the system. The following section will focus on this, and explain in more depth.
A typical CMS system stores content objects in a hierarchical folder structure similar to that of the file system. And, as every computer user knows, such a structure quickly gets difficult to use, especially when maintained by multiple users. The reason is that larger content sets rarely fit neatly into a tree structure, and having only one relationship type tends to obscure the intended purpose of each folder.
To combat this, traditional CMSs have offered additional capabilities such as attaching property-value metadata to content objects and allowing full-text search of the content object text. The full-text search capability, while useful for some purposes, does little to combat infoglut. The metadata feature, however, does offer some help, as alternative navigation systems can be implemented using structured queries. Unfortunately, this capability is rather weak, owing to the simplicity of the metadata scheme.
Advanced CMSs have gone further by allowing content objects to be related by explicit links that serve as an augmentation to the folder system and the metadata. These links are used to indicate hyperlinks from the content of one object to that of another, and also in some cases to indicate conceptual relationships between content objects. In some systems these links can be typed, in others not. This capability is generally very useful, but its power tends to be somewhat curbed by its poor integration into the overall CMS system, which means that links are unrelated to folder structure and that metadata queries cannot also search links.
The classic CMSs have often also had other weaknesses, but for reasons of space and focus they will be ignored in this paper.
The above section should not lead one to forget that in a number of areas the traditional CMS has succeeded quite well. As this paper focuses on improving the weaknesses of CMSs we will not consider their strengths in any depth as they are in a sense outside the scope of this paper. As it is said, the healthy need no doctor.
A primary benefit of a CMS system has in many cases been the client/server model combined with the check-in/check-out metaphor, which has made it easy for users to collaborate, even in distributed environments. The quality of authoring environments has varied, but can hardly be called a weakness of CMS systems in general, and the same applies to the access control features. The support for versioning has, in the best CMS systems, been very good, and the same applies to workflow.
Several CMS professionals have independently of one another told me that "what is really needed is a CMS where the content objects float free, and are located and managed using their metadata only." This is essentially what an ITMS, or Integrated Topic Management System, is. Content objects are liberated from the folder straightjacket and a topic map is placed on top of them to allow them to be found and managed. That is the essential idea behind the ITMS concept[1]. To put it another way, an ITMS is a CMS where the organizing principle is the topic map model.
Architecturally, the system is divided into two parts: a topic map and a blob storage. The topic map holds the metadata, while the blob storage holds the actual content objects. These are referred to from the topic map which manages them. Thus, the content objects are accessed through a topic map rather than a folder structure, and metadata is now represented in topic map form. The basic structure of the classical CMS remains much as it was; the primary difference is the structure of the metadata.
The figure below shows a high-level outline of the architecture of the system; the user accesses the ITMS through the topic map, which is mounted on top of the blob storage.
High-level architecture
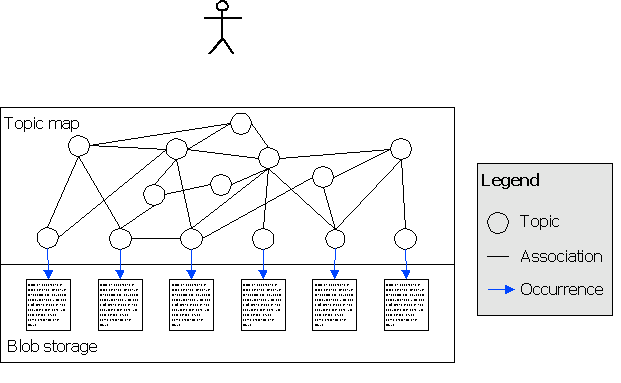
As the diagram hints, some of the topics in the topic map represent content objects, while others do not. The topics that do not represent content objects typically represent concepts such as engine X, parts Y and Z, country W, and guideline Q. These are then related to the topics representing content objects by means of associations that describe their relationships.
The content object topics use occurrences to connect to the actual
content objects in the blob storage. Topic maps use URIs for this
connection, which means that one can either use standard URI schemes
like http or define specialized URI schemes for these
references.
An alternative representation might be to not have topics representing the content objects, but to instead make them occurrences of all the concepts to which they are related. This approach works, but has the disadvantage that it makes it harder to attach metadata such as a name and other strings to the content objects. A way around this might be to reify the content object with a topic and still use occurrences for the connections, but if the content object has a topic, why not connect it to the relevant concepts by means of associations?
A goal for any ITMS implementation must be that its users should experience it as a single coherent system where the content is better organized than what is usual. For the implementor, however, one of the key issues is what to store in the topic map and what to store in the blob storage together with the content objects. That is, where to draw the boundary between the topic map itself and the storage system.
At first it may seem attractive to store simple metadata like "created by", "last modified on", and so on with the content objects rather than in the topic map. This creates a problem for a user interface built on the topic map, however, since this information will then not be available to the topic map application in topic map form. In other words, there will be no way to perform a query like "show me all content objects about subject X changed by user Y yesterday".
The obvious solution to this is to put absolutely all metadata in the topic map itself, and to leave only the content objects themselves in the storage layer. A reasonable representation would be to put information like "creation date" and "last modified on" in internal occurrences attached to the topic representing the content object, while "created by" and "last modified by" would be associations to topics representing users. This solves the problem above and also leads to other benefits, as we shall see later.
If all the metadata is to be stored in the topic map, this implies that all access to the CMS must happen through the topic map. Requiring access to be through the topic map makes it possible for the ITMS to keep the metadata up to date automatically. In some cases, however, one might want to turn an existing CMS system into an ITMS, and in these cases the accesses to the content objects would happen outside the control of the ITMS, as shown below.
ITMS with double-sided access
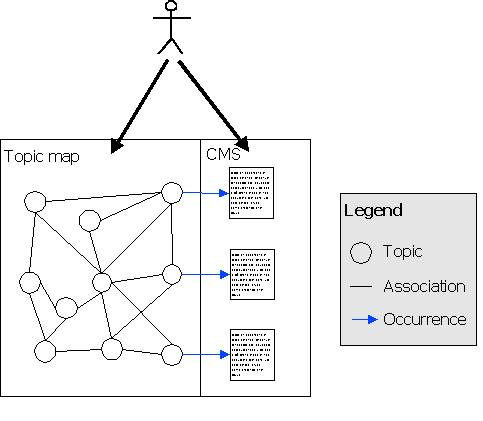
Such a system might be desirable in cases where a CMS is already successfully implemented in an organization since the topic map could then be mounted on top of an already running CMS and link into it, extending the CMS with new capabilities, without requiring changes to the CMS itself. An alternative scenario where the same architecture may be desirable is in cases where a CMS vendor wishes to add topic map capabilities to their CMS product by integrating a topic map engine into it.
In these cases the problem could be solved by creating an adapter that mirrors the metadata attached to the content objects inside the topic map. This could be done by creating a virtual topic map that is built lazily by pulling information out of the CMS "on demand", or by adding triggers to the CMS which automatically update the ITMS structure when the CMS structure is updated.
In order for the separation of the ITMS into a topic map layer and a blob storage layer to work, the blob storage layer must provide a number of operations to the ITMS. That is, the ITMS must be able to ask the blob storage layer to perform certain tasks on its behalf. This "asking" may take the form of method calls in an API or requests in a network protocol. How the requests are represented is an issue we will return to; for now we will only consider what primitives are necessary.
The operations are divided into two groups: the core set needed in the case where all metadata resides in the topic map, and the more extensive set needed in cases where access happens outside the control of the topic map.
The core set consists of the following operations:
This operation returns the contents of the resource with the given URI.
This operation takes the given URI and replaces the contents of the corresponding resource with the contents provided in the request. If the resource does not already exist it is created. The request is only allowed if the resource is not locked, in which case it will fail.
This operation locks the resource with the given URI, unless it has already been locked by someone else, in which case the request will fail.
This operation removes any locks on the resource with the given URI, provided such a lock is already held by this user. If there is no lock on this resource or it is held by a different user the request fails.
This operation deletes the resource with the given URI, unless the resource is locked, in which case the request will fail.
This core set of operations is all that is needed to implement the most basic form of blob storage layer. The requests can very easily be translated into an API which can then serve as an abstract interface that can be implemented to provide a blob storage to an ITMS. This interface can conceivably be implemented on top of the file system, an RDBMS, or some other form of storage.
A very interesting observation is that this set of operations is a subset of the WebDAV protocol, which is an extension of the HTTP protocol to support remote authoring of resources via HTTP [RFC2518]. This means that a WebDAV server can serve as a blob storage layer in an ITMS, enormously expanding the set of systems which can be integrated into an ITMS with little effort.
If the architecture of the system is such that users modify the contents of the CMS without going through the topic map application, more operations are needed. These include the ability to access the properties of resources, to traverse the folder hierarchy, and also to access the various versions of each content object. The WebDAV protocol provides support for the first two, but not for the last, though this can be found in the versioning extensions to the WebDAV protocol described in [RFC3253].
The previous section describes an abstract protocol where requests to the storage layer are passed on as URIs and no further thought is given to how the storage layer actually interprets these URIs. This provides a great deal of architectural freedom, in that it allows us implement several different scenarios with the same basic structure:
Simplest is the system where there is only a single content store, and all new content objects get URIs that point into it using a convention defined by the storage layer.
A more ambitious approach is to use the protocol to provide access to a number of different content stores, distinguished from one another by means of the URI of each content object. The topic map need not know about this distinction; it can be implemented entirely inside the storage layer by means of URI comparison.
In short, the system can start out with a single content store, and grow to include more content stores with time.
The adoption of topic maps as the organizing principle for a CMS brings several immediate benefits. The most obvious is that of greatly increased findability of the system's content due to the improved metadata representation. Content will now be explicitly linked with the concepts it relates to, and those concepts in turn will be carefully described by crosslinks. The result is that for each content object multiple redundant navigation paths lead there, all clearly marked and signposted with meaningful association types.
A less obvious, but perhaps more important improvement, is the improved ease of maintenance brought by the new organization of the content. Updates of content tend to be brought on by changes in the real world, which the content then needs to be updated to reflect. A technical documentation system must be updated because engine X now uses part Y instead of part Z, or an encyclopedia must be updated due to changes in the political landscape in country W, or guideline Q in a large documentation system changes.
In the case of the documentation system, documents relevant to engine X, part Y, and part Z must now be examined to see what needs to be changed. With a topic map this task is greatly simplified. The user can navigate to the three topics representing the engine and the two parts and examine the documents related to each, as well as any other concepts related to these three things that might also need revision.
The case of the encyclopedia is similar. The user will locate the topic representing country W to see if there are topics on its politics, history, and perhaps even parties that need updating. The associations to related concepts helps the user find all related content, such as the geographic region and contents about politics in general as well, to see if anything there needs updating.
Guideline Q, however, is a different matter. A number of documents expand on guideline Q, and there is a whole tree of references and dependencies spreading out from it, all represented using associations. Using a query on the topic map, the user can immediately find all documents that depend on guideline Q, directly or indirectly, and then sit down to work out what needs to be assigned to which workflow in order for the content to correctly reflect the change in Q. (In theory the workflows might even be started automatically for all dependent documents by the change to Q.)
In all of these cases, updates were simplified because of the more precise metadata structure allowed by the topic map model, and the fact that the system contains not only metadata, but also metametadata. That is, not only did the system record that content object A was the maintenance manual of engine X, but it also recorded the relationships between engine X and parts Y and Z and other related concepts.
Parts of a topic map
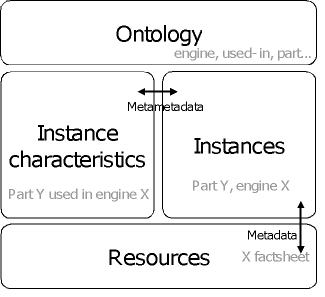
The diagram above shows the separation of the topic map into four distinct parts. The lowest level is the actual content objects (or resources), which is what is stored in the blob storage layer. Immediately above them are the concepts discussed in the content, directly or indirectly, and above this again is the information about these concepts. Finally, at the top is the ontology, which defines what we can say at all in this topic map.
As the diagram shows, metadata is attaching the relevant concepts to the content objects, for example that this is the factsheet for engine X and that it was last modified by user A. Metametadata, on the other hand, is information about these concepts, such as that user A works in department B, and that engine X contains part Y. Unlike most other metadata schemes topic maps do not distinguish between these levels and allow you to say what you will about the content and the concepts discussed therein. This is what gives topic maps their tremendous power to organize content, and as we will see below, that has other benefits as well.
A related benefit of annotating the content with a topic map is that the metadata may be useful not just to those who maintain the content, but also to those who use it. That is, the topic map layer above the content is really a distillation of the information found in textual form in the content (such as that part Y is used in engine X). This information would be valuable to the users in its own right, even were it not connected to the textual content in the system.
In other words, it is clear that when publishing the content in the content objects it may be useful to also publish the topic map about that content. In a web environment this can be done by making topic maps provide the structure to the web site where the content is published. The web site thus becomes topic map-driven with all the findability and flexibility benefits that entails, and at no extra cost, since this information is already used to run the ITMS.
When publishing to traditional media such as paper it is harder to exploit the topic map to the full, since following references is harder in a paper-based system, but creating an index publication based on selected extracts from the topic map is certainly possible. This might take the form of tables listing what concepts are discussed where, tree diagrams showing tree structures, and similar navigational aids.
Having metametadata in the CMS brings yet another benefit: the metametadata tends to correspond to what the Knowledge Management community calls "tacit knowledge". This is the sort of thing some of the people in an organization know, but never wrote down. Tacit knowledge can only be passed on orally, which is an awkward way to pass on knowledge. The goal of knowledge management is to have as much of the tacit knowledge as possible recorded in some form.
This means that an ITMS, if decorated with metametadata, really becomes both a CMS and knowledge management system. To fully realize this potential to the, organizations should consider developing the metametadata layer of their ITMSs a goal in its own right. If they do they get two systems in one; if they don't they get only a single system, but one that can later be extended.
One benefit of placing a standard like topic maps at the foundation of the CMS system is that it is no longer necessary to invent and implement a metadata framework for the system. Doing so is often a laborious process that requires much thinking. Using topic maps allows the implementor to leverage the work done by the topic maps community over the past decade instead of duplicating it himself. All an ITMS implementor needs to is to pick a suitable topic map implementation among several alternatives and build the CMS on top of that, either as a resellable product or as a one-off project. This is likely to provide a more solid foundation than doing it yourself, and also saves effort.
A related benefit is that since the entire structure of the ITMS is in the form of a topic map with related content object the whole thing can be exported to the XTM 1.0 syntax [XTM1.0]. This means portability of information across installations, but also gives users the ability to jump ship from one implementation to another, since the entire CMS system can be expressed in XTM form.
Furthermore, once the TMQL query language is completed it can be used as the query language for the entire CMS system[2]. This has several benefits such as not having to implement a query system yourself, which also means that the query language is likely to be more powerful than if you had developed it yourself. In addition, applications using TMQL will be portable across different implementations.
A similar benefit follows from the existence of the TMCL schema language. Using this, the allowed structure of the ITMS can be declared and validated. Most CMS systems which support some form of extensibility also provide some way of limiting the freedom of users. These mechanisms are usually not very powerful, and it seems fair to expect that TMCL will provide much more extensive capabilities[3].
As described in section 4.3. the ITMS can be used to integrate separate CMSs. This is a significant capability as [Bronder02] found that out of 800 companies polled 15% had invested in more than one CMS. Quite often companies implement one CMS for textual content and another for managing information such as images, audio clips, and video. With an ITMS this is no longer necessary, and the ITMS can also be used to bridge these disparate systems.
The introduction of an ITMS can even, in the longer run, provide benefits not directly related to the management of the content within it. One example is that since the mechanism used to connect the topic map to content objects is URIs the topic map can conceivably be used to manage content that is not physically stored within the ITMS. In fact, the content may not even be owned by the organization that owns the ITMS.
Such external content may be in one of two categories: modifiable content and read-only content. The first category can essentially be treated like any other content outside the control of the ITMS provided its storage supports the abstract protocol described in section 3.3.. The second category may be read-only because its storage does not support the necessary parts of the protocol or because the content is not owned by the organization that owns the ITMS. The content can still be managed to some extent from within an ITMS provided GET is implementable.
Topic maps greatly simplify the process of merging information from disparate sources, and so also with CMS content. By using topic maps it becomes much easier to integrate information from other sources into the ITMS, and also to reuse ITMS information outside the ITMS.
Most workflow systems have limitations in what functionality they support. For example, usually a single content object can only participate in one workflow at a time. With topic maps it becomes easy to express more complicated workflows, and also to allow content objects to participate in more than one workflow. Using TMCL order can still be imposed on the topic map.
A similar benefit applies to user management and access control. Usually CMSs have assigned each user to a group, and then set read/write access rights for each group and content type. With topic maps the group information can be derived from metadata attached to the user topic (department, position, etc) and the relationship between content object class and access rights can be more flexible.
For example, there will most likely be a superclass/subclass hierarchy of content object classes, which simplifies the expression of access rights, and at the same time allows it to be finer-grained.
In summary, it appears clear that topic maps have much to offer the traditional content management system, and at little cost. The primary benefits are findability, improved ease of maintenance, improved metadata for use in published content, and the benefits following from using a standards-based model.
The combination of topic maps and WebDAV is especially interesting, as it allows the topic map to be layered on top of any system that supports the WebDAV protocol. Given that most CMSs today as well as many other systems do support WebDAV, this combination is very promising.
It does not seem too optimistic to forecast that ITMS products will be available before the end of 2003. Indeed, one of my readers claim that they already are...
Some of the ideas for what topic maps can bring to content management are due to Stian Danenbarger, in personal communication with the author.
The term ITMS is due to Al J. Klein.
The paper has been informed by useful discussions on the subject with James David Mason and Steve Pepper. Steve Pepper also provided useful feedback on the prose, helped me curb my natural inclination to bite off too much in one bite, and suggested what is now section 3.4..
Some of the ideas in this paper were developed in collaboration with Geir Ove Grønmo.
| 1 | The idea is of course not new. An early presentation of it can be found in [Ahmed00] and a variation on the same theme also appears in [Pepper99]. |
|---|---|
| 2 |
The ISO TMQL standard is not yet finished, but in the meantime several non-standard languages are available. |
| 3 | Again, while TMCL is not here yet, several alternatives already exist. |