| By: | Steve Pepper, Founder and Chief Strategy Officer |
|---|---|
| Affiliation: | Ontopia |
| Email: | pepper@ontopia.net |
| Web: | www.ontopia.net |
| By: | Sylvia Schwab, Partner Manager |
| Affiliation: | Ontopia |
| Email: | sylvia@ontopia.net |
| Web: | www.ontopia.net |
|
This paper describes the crisis of identity facing the World Wide Web and, in particular, the RDF community. It shows how that crisis is rooted in a lack of clarity about the nature of "resources" and how concepts developed during the XML Topic Maps effort can provide a solution that works not only for Topic Maps, but also for RDF and semantic web technologies in general.
Steve Pepper is the founder and Chief Strategy Officer of Ontopia, a company that provides topic map software, consulting, and training services.
Steve represents Norway on JTC1/SC34, the ISO committee responsible for the development of SGML and related standards, and is convenor of WG3 (Information Association), whose responsibilities include the HyTime and Topic Map standards. He is the editor of the XML Topic Map specification (XTM) and the author of numerous papers and presentations on topic map-related subjects, including the well-known "TAO of Topic Maps".
A frequent speaker at SGML, XML, and knowledge management events around the world, Steve was for many years the author and maintainer of the "Whirlwind Guide to SGML and XML tools". He also co-authored (with Charles Goldfarb and Chet Ensign) the "SGML Buyer's Guide" (Prentice-Hall, 1998).
Sylvia Schwab co-founded Ontopia in 2000. As Partner Manager, Sylvia develops and manages Ontopia's Partner Programme.
Prior to joining Ontopia Sylvia worked for fours years as a Project Manager and Information Architect for STEP GmbH in Germany and STEP Infotek in Norway. She was responsible for the management and execution of projects involving document management solutions, as well as consulting projects in XML-based information process re-engineering.
Sylvia is trained as a the computer scientist from the University of Applied Science in Würzburg, Germany.
In an important recent article on XML.com entitled "Identity Crisis" [Clark 2002], Kendall Clark addresses the issue of "identity" as it pertains to the World Wide Web. Clark quotes the description of the Web by the W3C's Technical Architecture Group (TAG) in Architecture of the World Wide Web [Jacobs 2002], as a "universe of resources", where "resource" is to be understood according to the definition given in [RFC 2396] as being "anything that has identity". Clark points out that the concept of "identity" itself is nowhere defined and moreover is severely problematic.
Clark's article is part of a long-standing and on-going discussion in the Web community. As Sandro Hawke points out: "This is an old issue, and people are tired of it, but the issue continues to complicate the lives of RDF users". Tim Berners-Lee, after finding himself in a minority in the W3C TAG, has found it important enough to justify a position paper of his own, entitled What do HTTP URIs Identify? [Berners-Lee 2003]. Other important contributions have been David Booth's Four Uses of a URL [Booth 2003] and Sandro Hawke's Disambiguating RDF Identifiers [Hawke 2002], among many others.
The heart of the matter is the question "What do URIs identify?" Today there is no consistent answer to this question, as Hawke notes:
To date, RDF has not been clear about whether a URI like "http://www.w3.org/Consortium" identifies the W3C or a web page about the W3C. Throughout RDF, strings like "http://www.w3.org/1999/02/22-rdf-syntax-ns#type" are used with no consistent explanation of how they relate to the web.
Clark broadens the discussion to cover the whole issue of "What is a resource?" His example is different, but his point is the same:
URIs may well identify one resource each, but which one? Or, rather, if this is the case, why do developers tend to confuse or conflate resources? A URI like http://clark.dallas.tx.us/kendall cannot, if we take [Jacobs 2002] seriously, identify the resource we might call "Kendall Clark's home page" and the resource we might call "the natural person Kendall Clark". And yet there are perpetual conversations in the development community about, say, which resource one's home page identifies, about overloading the URI of one's home page to identify both oneself and one's home page, and so on.
Why is this important? Because without clarity on this issue, it is impossible to solve the challenge of the Semantic Web, and it is impossible to implement scaleable Web Services. It is impossible to achieve the goals of "global knowledge federation" and impossible even to begin to enable the aggregation of information and knowledge by human and software agents on a scale large enough to control infoglut.
Ontologies and taxonomies will not be reusable unless they are based on a reliable and unambiguous identification mechanism for the things about which they speak. The same applies to classifications, thesauri, registries, catalogues, and directories. Applications (including agents) that capture, collate or aggregate information and knowledge will not scale beyond a closely controlled environment unless the identification problem is solved. And technologies like RDF and Topic Maps that use URIs heavily to establish identity will simply not work (and certainly not interoperate) unless they can rely on unambiguous identifiers.
A solution to the "identity crisis of the Web" is clearly essential. The purpose of this paper is to offer an explanation of the root causes of the problem and to show how concepts originally developed as part of XML Topic Maps (XTM) [Pepper 2001] offer a solution that can be applied to the semantic web in general.
A simple example, taken from the current draft of the RDF Primer [Manola 2003], demonstrates the total reliance of semantic web technologies like RDF and Topic Maps on URIs:
Using URLs as identifiers in RDF
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:contact="http://www.w3.org/2000/10/swap/pim/contact#">
<contact:Person rdf:about="http://www.w3.org/People/EM/contact#me">
<contact:fullName>Eric Miller</contact:fullName>
<contact:mailbox rdf:resource="mailto:em@w3.org"/>
<contact:personalTitle>Dr.</contact:personalTitle>
</contact:Person>
</rdf:RDF>
This example says that there exists someone whose name is Eric Miller, whose email address is em@w3.org, and whose title is Dr. It actually contains no fewer than eight URIs: In addition to the four URIs that are given explicitly, the four element types Person, fullName, mailbox, and personalTitle each correspond to URIs in the "contact" namespace. Any ambiguity about the identities represented by any of those URIs will cause this fragment of RDF to be misinterpreted and incorrectly processed.
To illustrate the potential problem, let us focus on one of those URIs, "http://www.w3.org/People/EM/contact#me", which is used to identify the subject, Eric Miller. This URI actually resolves to the following information resource:
The information resource at http://www.w3.org/People/EM/contact#me
<?xml version="1.0" ?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns="http://www.w3.org/2000/10/swap/pim/contact#">
<Person rdf:about="http://www.w3.org/People/EM/contact#me">
<rdf:value>Eric Miller, em@w3.org</rdf:value>
<mailbox rdf:resource="mailto:em@w3.org" />
<fullName>Eric Miller</fullName>
<personalTitle>Semantic Web Activity Lead</personalTitle>
<company>W3C World Wide Web Consortium</company>
<phone>614.763.1100</phone>
</Person>
</rdf:RDF>
That information resource was created or made available by some person at some date. It would be perfectly legitimate to want to assert these facts in the form of metadata about the information resource, for example using Dublin Core vocabulary. The only way to identify the subject of these new assertions would be to use the same URI:
Using the same URI to identify a different subject
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.0/">
<rdf:Description rdf:about="http://www.w3.org/People/EM/contact#me">
<dc:creator>Eric Miller</dc:creator>
<dc:date>2002/06/04</dc:date>
</rdf:Description>
</rdf:RDF>
So we have one and the same URI being used to identify two quite distinct subjects, Eric Miller himself, and the resource that contains information about Eric Miller. An application that wanted to aggregate the assertions shown in these examples would end up considering the Person named Eric Miller to have been created on April 6th 2002, because all the assertions in the three examples appear to have been made about the same subject. If that application were attempting to make a doctor's appointment for Eric, as described in [Berners-Lee 2001], it would likely end up contacting a paediatrician!
The root of the problem is that one URI is being used in two quite distinct ways: to identify one subject directly and to identify another subject indirectly. Because no syntactic distinction is made between these two usages, an application has no way of telling them apart and ends up getting thoroughly confused.
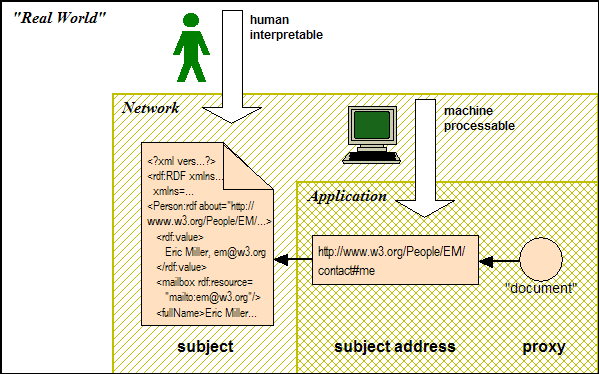
A URI like http://www.w3.org/People/EM/contact#me is a locator, or address. It resolves to an information resource and therefore can be used directly as an identifier for that resource, as in Figure 3. However, many of the subjects about which we want to make assertions are not information resources; they do not have network locations and therefore cannot be addressed, or identified, directly. In Figure 1, a locator is being used to identify such a "non-addressable" subject indirectly, via a resource that provides some indication of the subject's identity.
This indiscrimate use of URIs to identify subjects both directly and indirectly can be traced back to a lack of clarity regarding the very notion of "resource" in the Web community.
Historically, in the model originally envisioned by Tim Berners-Lee, resources were simply documents (information resources) that had locators. Those locators turned out to be very useful as identifiers for documents - for example, when attaching metadata to them. But as the Web matured a need arose to be able to make assertions about things that were not documents (e.g., people and organizations) and the same practice of using URLs as identifiers was simply extended without much thought for the consequences. This in turn led to the more general notion of "resource" as defined in [RFC 2396]:
A resource can be anything that has identity. Familiar examples include an electronic document, an image, a service (e.g., "today's weather report for Los Angeles"), and a collection of other resources. Not all resources are network "retrievable"; e.g., human beings, corporations, and bound books in a library can also be considered resources.
Now, with the advent of the semantic web, the shortsightedness of this approach is becoming clearly apparent.
Kendall Clark points out (correctly) that "RFC 2396's definition is indistinguishable from saying that a resource can be anything at all". But surely the distinction between a network-retrievable information resource and "everything else" is of fundamental importance to the whole architecture of the Web? The term "resource" obscures the fact that some of the things we want to identify have locations and others do not. Using a "locator" for something that has a location makes sense; using it for something that does not is asking for trouble.
This problem was recognized by TopicMaps.Org when the XML Topic Maps (XTM) specification was being developed and led to the concept of subject indicators. If the W3C were to adopt the same concept, it would both solve its own identity crisis and open the door for greater interoperability between Topic Maps and RDF.
In Topic Maps, a fundamental distinction is made between subjects which are addressable and subjects which are not. They are sometimes called "addressable subjects" and "non-addressable subjects", respectively.
In the case of addressable subjects (i.e., information resources such as the RDF document describing Eric Miller in Figure 2, above), a URI can be used to identify the subject directly. When used in this way, the URI is called a subject address.
Using a URL as a subject address to identify an information resource
The syntax for establishing the identity of such a subject using XTM (XML Topic Maps) is as follows:
Using a URL as a subject address in XTM
<topic id="about-eric">
<subjectIdentity>
<resourceRef xlink:href="http://www.w3.org/People/EM/contact#me"/>
</subjectIdentity>
<!-- creator, date, etc -->
</topic>
In this example, the use of a resourceRef element shows that the URI is being used as a subject address for an addressable subject. The subject is therefore the RDF document that resides at http://www.w3.org/People/EM/contact#me. This example therefore corresponds to Figure 3, where the intent is to attach Dublin Core metadata to the information resource.
When a URI is used to identify a subject indirectly, it is called a subject identifier (to distinguish it from subject address, a URI used to identify a subject directly). This is the case in Figure 1, which talks about the person Eric Miller. The URI references an information resource that provides some kind of compelling and unambiguous indication of the subject. A human can interpret the information resource and know what subject is being referred to. An information resource that is used in this manner is called a subject indicator.
The following diagram illustrates how a subject identifier references a subject indicator for the subject Eric Miller:
Using a URL as a subject identifier to identify a non-addressable subject

The XTM syntax for the example above might be as follows:
Using a URL as a subject identifier in XTM
<topic id="eric">
<subjectIdentity>
<subjectIndicatorRef xlink:href="http://www.w3.org/People/EM/contact#me"/>
</subjectIdentity>
<!-- name, mailbox, title, etc -->
</topic>
In this example, the use of a subjectIndicatorRef element shows that the URI is being used as a subject identifier for a non-addressable subject. The subject is whatever is indicated by the RDF document that resides at http://www.w3.org/People/EM/contact#me. This example therefore corresponds to Figure 1, where the intent is to make assertions about the person Eric Miller.
Figures 5 and 7 show how Topic Maps recognizes the distinction between addressable and non-addressable subjects and provides a mechanism which allows URIs to be used in two distinct modes, as subject addresses or as subject identifiers. This makes it possible to avoid the ambiguity which is otherwise inherent in the use of URLs as identifiers.
In addition, the duality of subject indicators and subject identifiers provides an identification mechanism that works for both humans and applications: Equipped with a subject indicator, human users should be able to know exactly what subject is being referred to. Thus, whenever applications are considered media for human transactions, subject indicators provide a common reference to human users connected through the application, and agreement on the subject indicator can be used as the external expression of agreement as to the identity of a subject.
Applications, on the other hand, can simply compare subject identifiers in order to know when two sets of assertions are about the same subject. This dual identification mechanism therefore constitutes a basis for agreement on the identity of subjects throughout the network: between applications, between users, and between applications and users.[1]
The identification mechanism offered by Topic Maps can solve the Web's identity crisis. The problem, as we have seen, is widely recognized in the Web community, including the W3C's Technical Architecture Group, as the following quote shows:
It is confusing and costly when people use the same URI to refer to different resources (i.e., where there is some inconsistency in usage compared to the authoritative meaning of the resource). Suppose company A uses http://example.com/coolcompany to refer to CoolCompany's home page, while company B uses http://example.com/coolcompany to refer to CoolCompany. Company A then buys company B, but when they try to merge their databases, they cannot due to this inconsistent usage of the URI. [Jacobs 2002]
However, the TAG has no solution to offer, other than rather pathetic hand-waving, in the form of an exhortation to "avoid indiscriminate use" of URIs.
Others in the Web community have made more useful proposals, including Sandro Hawke, who suggests that the dual use of URIs be formally recognized in RDF. Hawke uses the terms "page-mode" and "subject-mode" to make exactly the same distinction as that made in Topic Maps between subject addresses and subject identifiers. For this to work, two changes are required to RDF. First of all, the RDF model (indeed, the model of the Web in general) must be adjusted to recognize the distinction between information resources and "things in general" (i.e., between addressable subjects and arbitrary subjects). Secondly, this change needs to be reflected in more precise syntax.
Regarding the latter, there are two approaches that can be taken: Either the syntactic structure of the URI itself can indicate whether the URI is a subject address or a subject identifier; or else the syntactic context in which the URI is used can determine its role. [Booth 2003] calls these approaches "different names" and "different contexts", respectively.[2]
Proposals have been made in the web community to go with the first approach (syntactic structure) and let the interpretation hinge on the use of the "#" symbol:
Some RDF users ... have been using the URI/URI-Ref distinction to help disambiguate between page-mode and subject-mode identification. Essentially, we used "#" as a flag to show when we were talking about arbitrary things instead of web pages. [Hawke 2002].
The problem with this solution - indeed with any solution based on the syntactic structure of the URI - is that it disregards the fact that any URI can be used in either "mode". A URI containing a fragment identifier (such as http://www.w3.org/People/EM/contact#me) also refers to an information resource.
The alternative is to let the syntactic context decide and this is the approach used in Topic Maps. As we have seen in Figures 4 and 5, the XML Topic Map (XTM) syntax provides two element types called <resourceRef> and <subjectIndicatorRef> to distinguish between URIs used as subject addresses and URIs used as subject identifiers, respectively.
[Hawke 2002] proposes a hybrid solution for RDF combining syntactic structure (1) and syntactic context (2 and 3), as follows:
The Rule: In RDF, each occurrence of a URI is either a subject-mode identifier or a page-mode identifier. It is subject-mode identifier if and only if (1) it has a "#" in it, (2) it is in the predicate role, or (3) it is in the object role of a triple where the predicate is rdf:type.
This hybrid approach seems unnecessarily complicated to us, and it also has the disadvantage, recognized by Hawke, that it "does not give people a way to talk, in RDF, about fragments of web pages or things which are the subject of an entire web page." The Topic Maps approach of using syntactic context alone is clearly both cleaner and simpler.
Exactly how syntactic context should be established is left as an exercise for the RDF community. However, we venture here a simple (and incomplete) syntax proposal in order to make the point as clear as possible.
Referring back to Figure 1, we see that the subject about which statements are being made is identified via an "about" attribute:
<contact:Person rdf:about="http://www.w3.org/People/EM/contact#me">
As we have seen, the URI shown here could also refer to the information resource (or document) at that location. This ambiguity can be resolved by the simple expedient of making the "about" attribute more precise, for example by distinguishing between "subject" and "indicator", as follows:
<contact:Document rdf:subject="http://www.w3.org/People/EM/contact#me"> <dc:date>2002/06/04</dc:date> </contact:Document>
In this example, we are obviously talking about the information resource as a subject in its own right and stating when it was created. In the following example, it is equally clear that the information resource is being used as a subject indicator in order to indirectly identify the more ineffable subject of Eric Miller:
<contact:Person rdf:indicator="http://www.w3.org/People/EM/contact#me"> <contact:fullName>Eric Miller</contact:fullName> <contact:personalTitle>Dr.</contact:personalTitle> </contact:Person>
Obviously, the attribute names shown here are merely proposals. Alternative attribute names might be "address" and "identifier" for subject and indicator, respectively.
The widely recognized "identity crisis" of the Web is due to the absence of a formal distinction between information resources and subjects in general. This can be traced back to the definition of "resource" in [RFC 2396].
Recognition of the important distinction made in Topic Maps between addressable and non-addressable subjects leads to the notion of subject indicators as an indirection mechanism for establishing the identity of subjects that cannot be addressed directly.
This allows URIs to be used in two ways - as subject addresses or as subject identifiers - without ambiguity. Syntactic context can be used to determine which mode is intended in any specific instance.
The concept of subject indicators also provides a powerful two-sided identification mechanism that can be used by both humans and applications.
For RDF and other semantic web technologies to take advantage of this mechanism, changes are required in the underlying data model of RDF and the basic architecture of the Web. Once these are made, the foundation will have been laid for achieving the goals of the semantic web.
Certain portions of this paper are based on a draft prepared by one of the present authors on behalf of the OASIS Published Subjects Technical Committee for its first deliverable, Published Subjects - Introduction and Requirements [Pepper 2003]. The authors wish to acknowledge the input of members of the TC, in particular its chair, Bernard Vatant, who prepared the original draft of that document.
We also wish to thank Pam Gennusa for forcing us to rewrite this paper from scratch in order to make it understandable, and Lars Marius Garshol for his contributions to the ideas expressed herein. We refer readers to an important paper by him ([Garshol 2003b]) that in many ways complements this one.
| 1 |
The idea of subject indicators leads to the immensely important concept of published subjects. Unfortunately, that topic is outside the scope of this paper. Readers are encouraged to review the work of the OASIS Published Subjects Technical Committee, in particular its first deliverable [Pepper 2003]. |
|---|---|
| 2 |
Booth actually believes that URLs can be used in four ways, rather than just the two we have discussed. We disagree, but it is outside the scope of this paper to go into the details. |